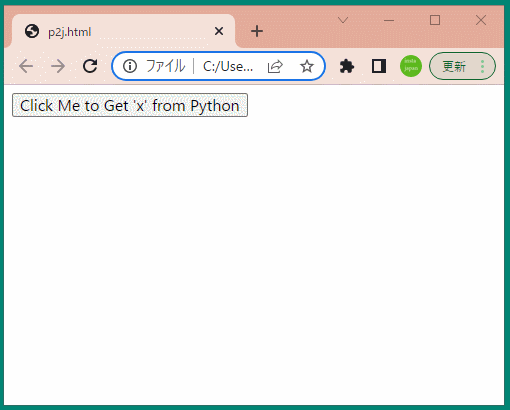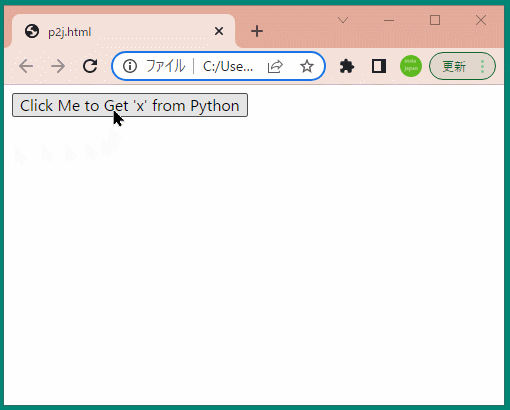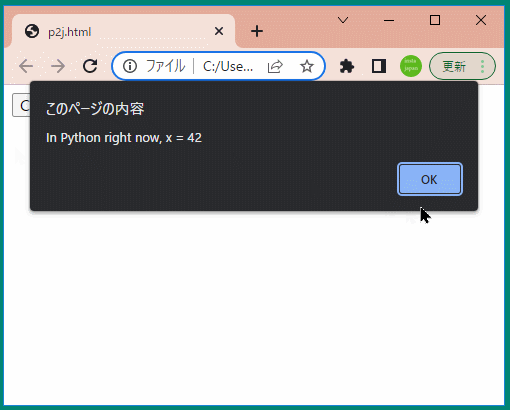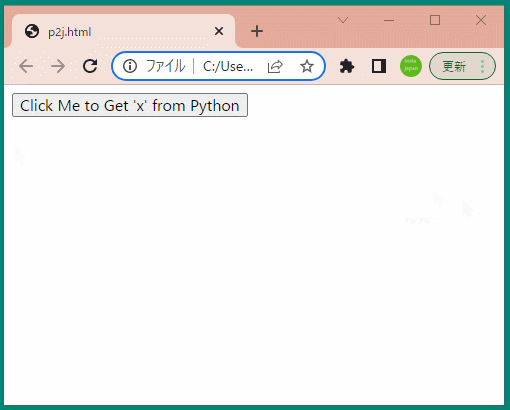
問題
$ N $ 個の商品があり、商品 $ i (1 \leqq i \leqq N)$の価格は $ A_i $ 円です。
異なる3つの商品を選び、合計価格をちょうど1000円にすることができるでしょうか。
答えをYesかNoで出力して下さい。
[制約]
🔹$ 3 \leqq n \leqq 100 $
解き方・ソースコード
この問題は3重ループを使うことで解くことができます。
1つめのループは全商品をチェックするために、$ N $ 回実行します。
2つめのループは1つめの商品と同じ商品を選ばないように、$ N - 1 $ 回実行します。
3つめのループは1つめ、2つめの商品と同じ商品を選ばないように、$ N - 2 $ 回実行します。
3重ループの中では、選んだ3つの商品の合計が1000円かどうかを確認します。
[Google Colaboratory]
1 | #--------- 入力例1 ---------- |
[実行結果(入力例1)]
No
与えられた3つの価格では1000円になることはないので、解はNoとなります。
[実行結果(入力例2)]
Yes
与えられた5つの価格のうち、[100, 400, 500]を選択すると1000円になりますので、解はYesとなります。