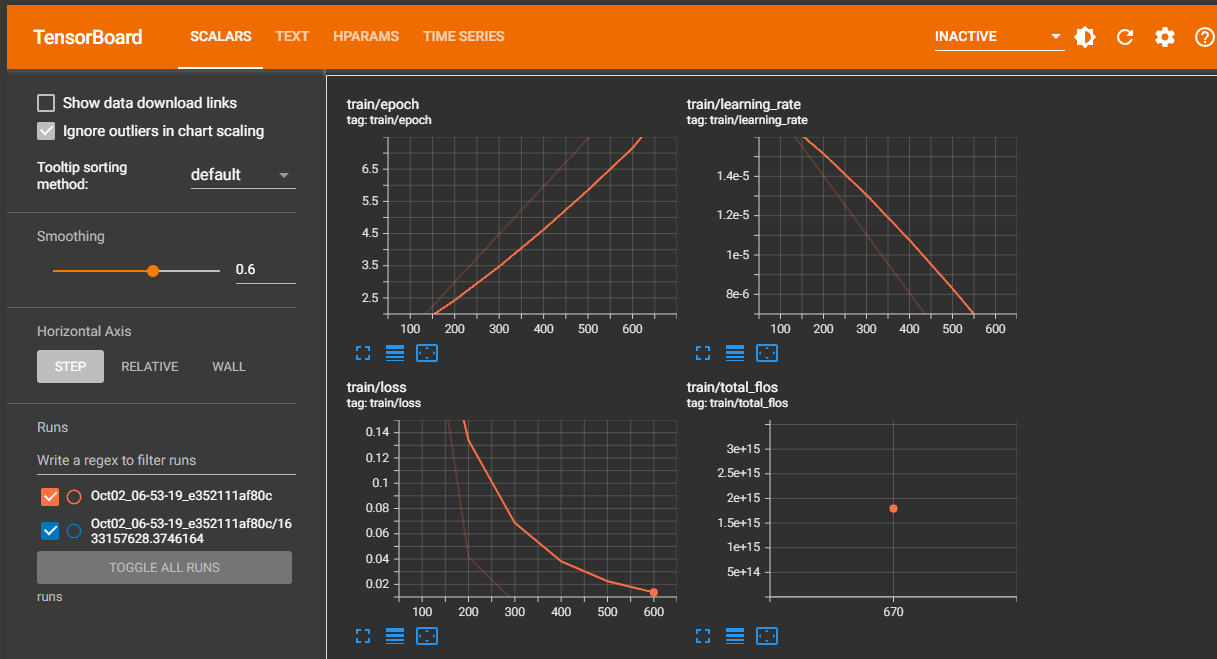
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
| 10/02/2021 06:53:19 - WARNING - __main__ - Process rank: -1, device: cuda:0, n_gpu: 1distributed training: False, 16-bits training: False
10/02/2021 06:53:19 - INFO - __main__ - Training/evaluation parameters TrainingArguments(output_dir=output/, overwrite_output_dir=True, do_train=True, do_eval=True, do_predict=False, evaluation_strategy=IntervalStrategy.NO, prediction_loss_only=False, per_device_train_batch_size=32, per_device_eval_batch_size=8, gradient_accumulation_steps=1, eval_accumulation_steps=None, learning_rate=2e-05, weight_decay=0.0, adam_beta1=0.9, adam_beta2=0.999, adam_epsilon=1e-08, max_grad_norm=1.0, num_train_epochs=10.0, max_steps=-1, lr_scheduler_type=SchedulerType.LINEAR, warmup_ratio=0.0, warmup_steps=0, logging_dir=runs/Oct02_06-53-19_e352111af80c, logging_strategy=IntervalStrategy.STEPS, logging_first_step=False, logging_steps=100, save_strategy=IntervalStrategy.STEPS, save_steps=500, save_total_limit=None, no_cuda=False, seed=42, fp16=False, fp16_opt_level=O1, fp16_backend=auto, fp16_full_eval=False, local_rank=-1, tpu_num_cores=None, tpu_metrics_debug=False, debug=False, dataloader_drop_last=False, eval_steps=100, dataloader_num_workers=0, past_index=-1, run_name=output/, disable_tqdm=False, remove_unused_columns=True, label_names=None, load_best_model_at_end=False, metric_for_best_model=None, greater_is_better=None, ignore_data_skip=False, sharded_ddp=[], deepspeed=None, label_smoothing_factor=0.0, adafactor=False, group_by_length=False, report_to=['tensorboard'], ddp_find_unused_parameters=None, dataloader_pin_memory=True, skip_memory_metrics=False, _n_gpu=1)
10/02/2021 06:53:19 - INFO - __main__ - load a local file for train: train.csv
10/02/2021 06:53:19 - INFO - __main__ - load a local file for validation: dev.csv
Downloading: 5.33kB [00:00, 4.14MB/s]
Using custom data configuration default
Downloading and preparing dataset csv/default-3977538288dff7b4 (download: Unknown size, generated: Unknown size, post-processed: Unknown size, total: Unknown size) to /root/.cache/huggingface/datasets/csv/default-3977538288dff7b4/0.0.0/2960f95a26e85d40ca41a230ac88787f715ee3003edaacb8b1f0891e9f04dda2...
Dataset csv downloaded and prepared to /root/.cache/huggingface/datasets/csv/default-3977538288dff7b4/0.0.0/2960f95a26e85d40ca41a230ac88787f715ee3003edaacb8b1f0891e9f04dda2. Subsequent calls will reuse this data.
[INFO|file_utils.py:1386] 2021-10-02 06:53:20,548 >> https://huggingface.co/cl-tohoku/bert-base-japanese-whole-word-masking/resolve/main/config.json not found in cache or force_download set to True, downloading to /root/.cache/huggingface/transformers/tmpx2iuwgdb
Downloading: 100% 479/479 [00:00<00:00, 423kB/s]
[INFO|file_utils.py:1390] 2021-10-02 06:53:20,673 >> storing https://huggingface.co/cl-tohoku/bert-base-japanese-whole-word-masking/resolve/main/config.json in cache at /root/.cache/huggingface/transformers/573af37b6c39d672f2df687c06ad7d556476cbe43e5bf7771097187c45a3e7bf.abeb707b5d79387dd462e8bfb724637d856e98434b6931c769b8716c6f287258
[INFO|file_utils.py:1393] 2021-10-02 06:53:20,673 >> creating metadata file for /root/.cache/huggingface/transformers/573af37b6c39d672f2df687c06ad7d556476cbe43e5bf7771097187c45a3e7bf.abeb707b5d79387dd462e8bfb724637d856e98434b6931c769b8716c6f287258
[INFO|configuration_utils.py:463] 2021-10-02 06:53:20,674 >> loading configuration file https://huggingface.co/cl-tohoku/bert-base-japanese-whole-word-masking/resolve/main/config.json from cache at /root/.cache/huggingface/transformers/573af37b6c39d672f2df687c06ad7d556476cbe43e5bf7771097187c45a3e7bf.abeb707b5d79387dd462e8bfb724637d856e98434b6931c769b8716c6f287258
[INFO|configuration_utils.py:499] 2021-10-02 06:53:20,674 >> Model config BertConfig {
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"id2label": {
"0": "LABEL_0",
"1": "LABEL_1",
"2": "LABEL_2"
},
"initializer_range": 0.02,
"intermediate_size": 3072,
"label2id": {
"LABEL_0": 0,
"LABEL_1": 1,
"LABEL_2": 2
},
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"position_embedding_type": "absolute",
"tokenizer_class": "BertJapaneseTokenizer",
"transformers_version": "4.4.2",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 32000
}
[INFO|configuration_utils.py:463] 2021-10-02 06:53:20,802 >> loading configuration file https://huggingface.co/cl-tohoku/bert-base-japanese-whole-word-masking/resolve/main/config.json from cache at /root/.cache/huggingface/transformers/573af37b6c39d672f2df687c06ad7d556476cbe43e5bf7771097187c45a3e7bf.abeb707b5d79387dd462e8bfb724637d856e98434b6931c769b8716c6f287258
[INFO|configuration_utils.py:499] 2021-10-02 06:53:20,803 >> Model config BertConfig {
"architectures": [
"BertForMaskedLM"
],
"attention_probs_dropout_prob": 0.1,
"gradient_checkpointing": false,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"position_embedding_type": "absolute",
"tokenizer_class": "BertJapaneseTokenizer",
"transformers_version": "4.4.2",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 32000
}
[INFO|file_utils.py:1386] 2021-10-02 06:53:20,926 >> https://huggingface.co/cl-tohoku/bert-base-japanese-whole-word-masking/resolve/main/vocab.txt not found in cache or force_download set to True, downloading to /root/.cache/huggingface/transformers/tmpjq6xsip6
Downloading: 100% 258k/258k [00:00<00:00, 3.12MB/s]
[INFO|file_utils.py:1390] 2021-10-02 06:53:21,164 >> storing https://huggingface.co/cl-tohoku/bert-base-japanese-whole-word-masking/resolve/main/vocab.txt in cache at /root/.cache/huggingface/transformers/15164357d71cd32532e56c1d7c2757141326ae17c53e2277bc417cc7c21da6ea.a7378a0cbee5cff668832a776d72b97a25479604fe9564d5595897f75049e7f4
[INFO|file_utils.py:1393] 2021-10-02 06:53:21,164 >> creating metadata file for /root/.cache/huggingface/transformers/15164357d71cd32532e56c1d7c2757141326ae17c53e2277bc417cc7c21da6ea.a7378a0cbee5cff668832a776d72b97a25479604fe9564d5595897f75049e7f4
[INFO|file_utils.py:1386] 2021-10-02 06:53:21,533 >> https://huggingface.co/cl-tohoku/bert-base-japanese-whole-word-masking/resolve/main/tokenizer_config.json not found in cache or force_download set to True, downloading to /root/.cache/huggingface/transformers/tmpvwenqgcb
Downloading: 100% 110/110 [00:00<00:00, 105kB/s]
[INFO|file_utils.py:1390] 2021-10-02 06:53:21,664 >> storing https://huggingface.co/cl-tohoku/bert-base-japanese-whole-word-masking/resolve/main/tokenizer_config.json in cache at /root/.cache/huggingface/transformers/0e46f722799f19c3f0c53172545108a4b31847d3b9a2d5b100759f6673bd667b.08ae4e4044742b9cc7172698caf1da2524f5597ff8cf848114dd0b730cc44bdc
[INFO|file_utils.py:1393] 2021-10-02 06:53:21,664 >> creating metadata file for /root/.cache/huggingface/transformers/0e46f722799f19c3f0c53172545108a4b31847d3b9a2d5b100759f6673bd667b.08ae4e4044742b9cc7172698caf1da2524f5597ff8cf848114dd0b730cc44bdc
[INFO|tokenization_utils_base.py:1702] 2021-10-02 06:53:21,789 >> loading file https://huggingface.co/cl-tohoku/bert-base-japanese-whole-word-masking/resolve/main/vocab.txt from cache at /root/.cache/huggingface/transformers/15164357d71cd32532e56c1d7c2757141326ae17c53e2277bc417cc7c21da6ea.a7378a0cbee5cff668832a776d72b97a25479604fe9564d5595897f75049e7f4
[INFO|tokenization_utils_base.py:1702] 2021-10-02 06:53:21,790 >> loading file https://huggingface.co/cl-tohoku/bert-base-japanese-whole-word-masking/resolve/main/added_tokens.json from cache at None
[INFO|tokenization_utils_base.py:1702] 2021-10-02 06:53:21,790 >> loading file https://huggingface.co/cl-tohoku/bert-base-japanese-whole-word-masking/resolve/main/special_tokens_map.json from cache at None
[INFO|tokenization_utils_base.py:1702] 2021-10-02 06:53:21,790 >> loading file https://huggingface.co/cl-tohoku/bert-base-japanese-whole-word-masking/resolve/main/tokenizer_config.json from cache at /root/.cache/huggingface/transformers/0e46f722799f19c3f0c53172545108a4b31847d3b9a2d5b100759f6673bd667b.08ae4e4044742b9cc7172698caf1da2524f5597ff8cf848114dd0b730cc44bdc
[INFO|tokenization_utils_base.py:1702] 2021-10-02 06:53:21,790 >> loading file https://huggingface.co/cl-tohoku/bert-base-japanese-whole-word-masking/resolve/main/tokenizer.json from cache at None
[INFO|file_utils.py:1386] 2021-10-02 06:53:21,968 >> https://huggingface.co/cl-tohoku/bert-base-japanese-whole-word-masking/resolve/main/pytorch_model.bin not found in cache or force_download set to True, downloading to /root/.cache/huggingface/transformers/tmpa845b2k1
Downloading: 100% 445M/445M [00:12<00:00, 36.5MB/s]
[INFO|file_utils.py:1390] 2021-10-02 06:53:34,325 >> storing https://huggingface.co/cl-tohoku/bert-base-japanese-whole-word-masking/resolve/main/pytorch_model.bin in cache at /root/.cache/huggingface/transformers/cabd9bbd81093f4c494a02e34eb57e405b7564db216404108c8e8caf10ede4fa.464b54997e35e3cc3223ba6d7f0abdaeb7be5b7648f275f57d839ee0f95611fb
[INFO|file_utils.py:1393] 2021-10-02 06:53:34,325 >> creating metadata file for /root/.cache/huggingface/transformers/cabd9bbd81093f4c494a02e34eb57e405b7564db216404108c8e8caf10ede4fa.464b54997e35e3cc3223ba6d7f0abdaeb7be5b7648f275f57d839ee0f95611fb
[INFO|modeling_utils.py:1051] 2021-10-02 06:53:34,325 >> loading weights file https://huggingface.co/cl-tohoku/bert-base-japanese-whole-word-masking/resolve/main/pytorch_model.bin from cache at /root/.cache/huggingface/transformers/cabd9bbd81093f4c494a02e34eb57e405b7564db216404108c8e8caf10ede4fa.464b54997e35e3cc3223ba6d7f0abdaeb7be5b7648f275f57d839ee0f95611fb
[WARNING|modeling_utils.py:1159] 2021-10-02 06:53:37,781 >> Some weights of the model checkpoint at cl-tohoku/bert-base-japanese-whole-word-masking were not used when initializing BertForSequenceClassification: ['cls.predictions.bias', 'cls.predictions.transform.dense.weight', 'cls.predictions.transform.dense.bias', 'cls.predictions.transform.LayerNorm.weight', 'cls.predictions.transform.LayerNorm.bias', 'cls.predictions.decoder.weight', 'cls.seq_relationship.weight', 'cls.seq_relationship.bias']
- This IS expected if you are initializing BertForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing BertForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
[WARNING|modeling_utils.py:1170] 2021-10-02 06:53:37,781 >> Some weights of BertForSequenceClassification were not initialized from the model checkpoint at cl-tohoku/bert-base-japanese-whole-word-masking and are newly initialized: ['classifier.weight', 'classifier.bias']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
100% 3/3 [00:00<00:00, 6.14ba/s]
100% 1/1 [00:00<00:00, 7.77ba/s]
10/02/2021 06:53:39 - INFO - __main__ - Sample 456 of the training set: {'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'input_ids': [2, 9680, 21436, 28589, 472, 19366, 9594, 1754, 35, 6006, 28645, 10622, 14, 14930, 25910, 18920, 3723, 28, 6, 1532, 35, 12590, 9, 36, 5342, 16, 80, 38, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'label': 1, 'sentence': '【Sports Watch】妻・SHIHOが凄艶ヌード披露も、夫・秋山は「聞いてない」', 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]}.
10/02/2021 06:53:39 - INFO - __main__ - Sample 102 of the training set: {'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'input_ids': [2, 63, 2000, 623, 6234, 7875, 29182, 17489, 6848, 65, 5, 612, 11, 2461, 104, 14, 16089, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'label': 2, 'sentence': '『劇場版 FAIRY TAIL』の一部を原作者が暴露', 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]}.
10/02/2021 06:53:39 - INFO - __main__ - Sample 1126 of the training set: {'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'input_ids': [2, 4623, 2710, 5, 3245, 21324, 237, 4158, 2720, 14, 690, 315, 40, 398, 971, 19, 126, 5, 28404, 11, 1174, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], 'label': 0, 'sentence': '進む資料のデジタルアーカイブ化\u3000国会図書館が明治時代から昭和27年までの官報を公開', 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]}.
[INFO|trainer.py:483] 2021-10-02 06:53:48,144 >> The following columns in the training set don't have a corresponding argument in `BertForSequenceClassification.forward` and have been ignored: sentence.
[INFO|trainer.py:483] 2021-10-02 06:53:48,145 >> The following columns in the evaluation set don't have a corresponding argument in `BertForSequenceClassification.forward` and have been ignored: sentence.
[INFO|trainer.py:946] 2021-10-02 06:53:48,352 >> ***** Running training *****
[INFO|trainer.py:947] 2021-10-02 06:53:48,352 >> Num examples = 2114
[INFO|trainer.py:948] 2021-10-02 06:53:48,352 >> Num Epochs = 10
[INFO|trainer.py:949] 2021-10-02 06:53:48,352 >> Instantaneous batch size per device = 32
[INFO|trainer.py:950] 2021-10-02 06:53:48,353 >> Total train batch size (w. parallel, distributed & accumulation) = 32
[INFO|trainer.py:951] 2021-10-02 06:53:48,353 >> Gradient Accumulation steps = 1
[INFO|trainer.py:952] 2021-10-02 06:53:48,353 >> Total optimization steps = 670
{'loss': 0.2883, 'learning_rate': 1.701492537313433e-05, 'epoch': 1.49}
{'loss': 0.0415, 'learning_rate': 1.4029850746268658e-05, 'epoch': 2.99}
{'loss': 0.0058, 'learning_rate': 1.1044776119402986e-05, 'epoch': 4.48}
{'loss': 0.0024, 'learning_rate': 8.059701492537314e-06, 'epoch': 5.97}
{'loss': 0.0019, 'learning_rate': 5.074626865671642e-06, 'epoch': 7.46}
75% 500/670 [09:48<03:22, 1.19s/it][INFO|trainer.py:1558] 2021-10-02 07:03:37,211 >> Saving model checkpoint to output/checkpoint-500
[INFO|configuration_utils.py:314] 2021-10-02 07:03:37,212 >> Configuration saved in output/checkpoint-500/config.json
[INFO|modeling_utils.py:837] 2021-10-02 07:03:38,494 >> Model weights saved in output/checkpoint-500/pytorch_model.bin
[INFO|tokenization_utils_base.py:1896] 2021-10-02 07:03:38,495 >> tokenizer config file saved in output/checkpoint-500/tokenizer_config.json
[INFO|tokenization_utils_base.py:1902] 2021-10-02 07:03:38,495 >> Special tokens file saved in output/checkpoint-500/special_tokens_map.json
{'loss': 0.0015, 'learning_rate': 2.08955223880597e-06, 'epoch': 8.96}
100% 670/670 [13:13<00:00, 1.13it/s][INFO|trainer.py:1129] 2021-10-02 07:07:01,701 >>
Training completed. Do not forget to share your model on huggingface.co/models =)
{'train_runtime': 793.3481, 'train_samples_per_second': 0.845, 'epoch': 10.0}
100% 670/670 [13:13<00:00, 1.18s/it]
[INFO|trainer.py:1558] 2021-10-02 07:07:02,143 >> Saving model checkpoint to output/
[INFO|configuration_utils.py:314] 2021-10-02 07:07:02,144 >> Configuration saved in output/config.json
[INFO|modeling_utils.py:837] 2021-10-02 07:07:03,410 >> Model weights saved in output/pytorch_model.bin
[INFO|tokenization_utils_base.py:1896] 2021-10-02 07:07:03,411 >> tokenizer config file saved in output/tokenizer_config.json
[INFO|tokenization_utils_base.py:1902] 2021-10-02 07:07:03,411 >> Special tokens file saved in output/special_tokens_map.json
[INFO|trainer_pt_utils.py:656] 2021-10-02 07:07:03,442 >> ***** train metrics *****
[INFO|trainer_pt_utils.py:661] 2021-10-02 07:07:03,442 >> epoch = 10.0
[INFO|trainer_pt_utils.py:661] 2021-10-02 07:07:03,442 >> init_mem_cpu_alloc_delta = 1MB
[INFO|trainer_pt_utils.py:661] 2021-10-02 07:07:03,442 >> init_mem_cpu_peaked_delta = 0MB
[INFO|trainer_pt_utils.py:661] 2021-10-02 07:07:03,442 >> init_mem_gpu_alloc_delta = 422MB
[INFO|trainer_pt_utils.py:661] 2021-10-02 07:07:03,442 >> init_mem_gpu_peaked_delta = 0MB
[INFO|trainer_pt_utils.py:661] 2021-10-02 07:07:03,443 >> train_mem_cpu_alloc_delta = 0MB
[INFO|trainer_pt_utils.py:661] 2021-10-02 07:07:03,443 >> train_mem_cpu_peaked_delta = 94MB
[INFO|trainer_pt_utils.py:661] 2021-10-02 07:07:03,443 >> train_mem_gpu_alloc_delta = 1324MB
[INFO|trainer_pt_utils.py:661] 2021-10-02 07:07:03,443 >> train_mem_gpu_peaked_delta = 3394MB
[INFO|trainer_pt_utils.py:661] 2021-10-02 07:07:03,443 >> train_runtime = 793.3481
[INFO|trainer_pt_utils.py:661] 2021-10-02 07:07:03,443 >> train_samples = 2114
[INFO|trainer_pt_utils.py:661] 2021-10-02 07:07:03,443 >> train_samples_per_second = 0.845
10/02/2021 07:07:03 - INFO - __main__ - *** Evaluate ***
[INFO|trainer.py:483] 2021-10-02 07:07:03,557 >> The following columns in the evaluation set don't have a corresponding argument in `BertForSequenceClassification.forward` and have been ignored: sentence.
[INFO|trainer.py:1775] 2021-10-02 07:07:03,559 >> ***** Running Evaluation *****
[INFO|trainer.py:1776] 2021-10-02 07:07:03,559 >> Num examples = 529
[INFO|trainer.py:1777] 2021-10-02 07:07:03,559 >> Batch size = 8
100% 67/67 [00:07<00:00, 9.09it/s]
[INFO|trainer_pt_utils.py:656] 2021-10-02 07:07:11,070 >> ***** eval metrics *****
[INFO|trainer_pt_utils.py:661] 2021-10-02 07:07:11,070 >> epoch = 10.0
[INFO|trainer_pt_utils.py:661] 2021-10-02 07:07:11,070 >> eval_accuracy = 0.9698
[INFO|trainer_pt_utils.py:661] 2021-10-02 07:07:11,070 >> eval_loss = 0.1554
[INFO|trainer_pt_utils.py:661] 2021-10-02 07:07:11,070 >> eval_mem_cpu_alloc_delta = 0MB
[INFO|trainer_pt_utils.py:661] 2021-10-02 07:07:11,071 >> eval_mem_cpu_peaked_delta = 0MB
[INFO|trainer_pt_utils.py:661] 2021-10-02 07:07:11,071 >> eval_mem_gpu_alloc_delta = 0MB
[INFO|trainer_pt_utils.py:661] 2021-10-02 07:07:11,071 >> eval_mem_gpu_peaked_delta = 33MB
[INFO|trainer_pt_utils.py:661] 2021-10-02 07:07:11,071 >> eval_runtime = 7.3979
[INFO|trainer_pt_utils.py:661] 2021-10-02 07:07:11,071 >> eval_samples = 529
[INFO|trainer_pt_utils.py:661] 2021-10-02 07:07:11,071 >> eval_samples_per_second = 71.507
CPU times: user 6.09 s, sys: 875 ms, total: 6.96 s
Wall time: 14min
|