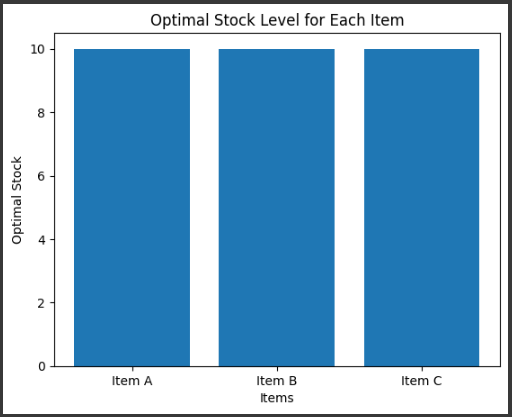
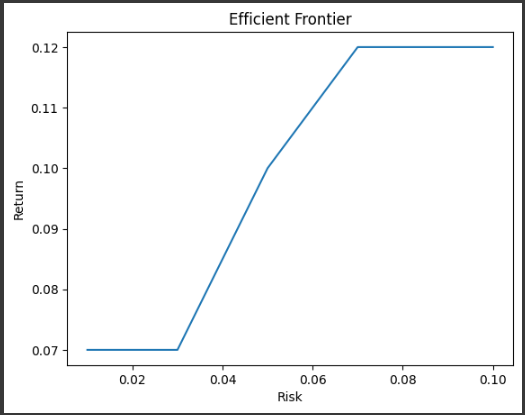
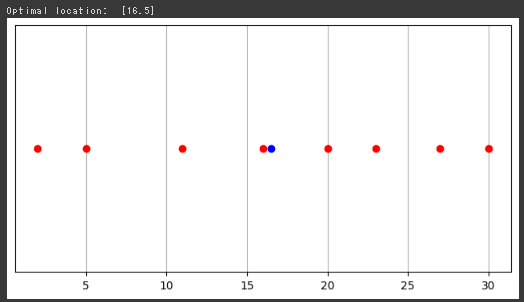
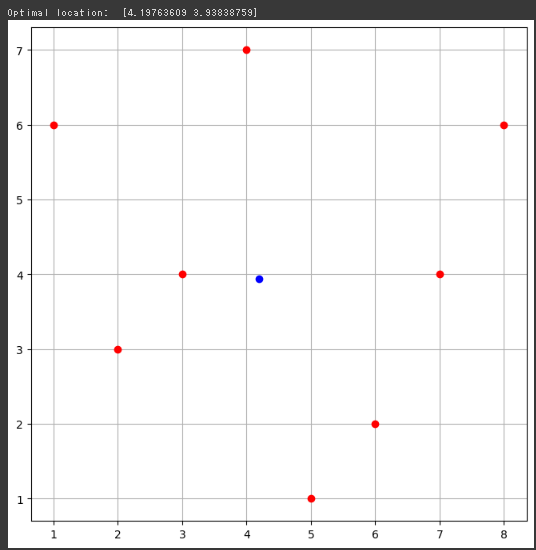
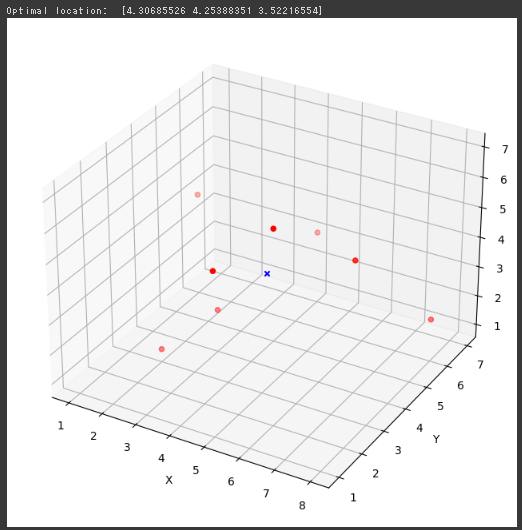
for risk_limit in risks_list: prob = LpProblem("Efficient Frontier", LpMaximize) x = LpVariable.dicts("x", assets, 0) prob += lpSum([returns[i]*x[i] for i in assets]) prob += lpSum([risks[i]*x[i] for i in assets]) <= risk_limit prob += lpSum([x[i] for i in assets]) == 1 prob.solve() returns_list.append(value(prob.objective))
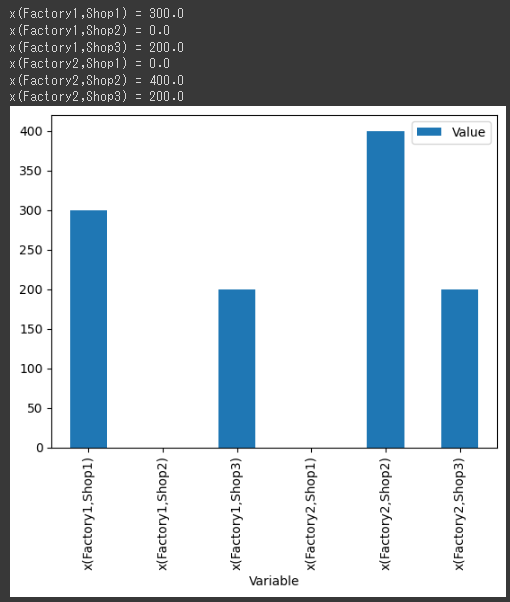
# 変数の定義 vars = { i: { j: LpVariable(f"x({i},{j})", lowBound=0) for j in demand_points } for i in supply_points }
# 目的関数の定義 prob += lpSum(costs[i][j] * vars[i][j] for i in supply_points for j in demand_points)
# 制約条件の定義 for i in supply_points: prob += lpSum(vars[i][j] for j in demand_points) <= supply_points[i] for j in demand_points: prob += lpSum(vars[i][j] for i in supply_points) >= demand_points[j]
# 問題の解法 prob.solve()
# 結果の表示 for v in prob.variables(): print(v.name, "=", v.varValue)
# 結果のグラフ化 df = pd.DataFrame([(v.name, v.varValue) for v in prob.variables()], columns=['Variable', 'Value']) df.plot(kind='bar', x='Variable', y='Value') plt.show()
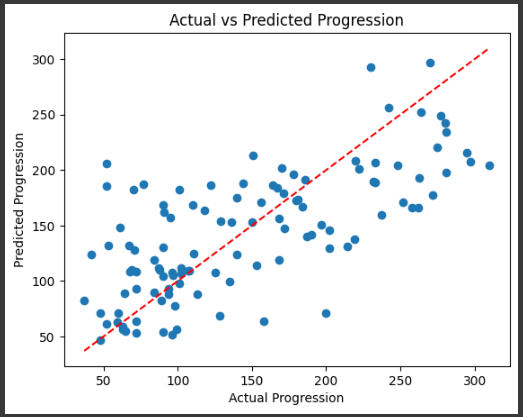
import numpy as np import pandas as pd from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error
import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.model_selection import train_test_split from sklearn.neighbors import NearestNeighbors