Finding Strategic Equilibrium Between Attackers and Defenders
Introduction
Imagine you’re a cybersecurity manager deciding how to allocate your limited defense budget. Your adversary — a rational attacker — is simultaneously deciding which systems to target. Neither of you knows exactly what the other will do, yet both of you are trying to optimize your outcome. This is precisely the setting where Game Theory shines.
In this post, we’ll model the attacker-defender interaction as a two-player zero-sum game, compute the Nash Equilibrium (mixed strategy), and visualize the strategic landscape in both 2D and 3D. We’ll use nashpy, scipy, and matplotlib — all runnable in Google Colaboratory.
Problem Setup
The Players
- Defender (Player 1): Chooses which of $m$ assets to protect (or how to allocate defense across assets).
- Attacker (Player 2): Chooses which of $n$ assets to attack.
The Payoff Matrix
Let $A \in \mathbb{R}^{m \times n}$ be the payoff matrix from the Defender’s perspective:
$$A_{ij} = \text{Defender’s payoff when defending asset } i \text{ and attacker targets asset } j$$
Since the game is zero-sum, the attacker’s payoff is $-A_{ij}$.
Nash Equilibrium (Mixed Strategies)
A mixed strategy Nash Equilibrium is a pair $(\mathbf{x}^*, \mathbf{y}^*)$ where:
$$\mathbf{x}^* = \arg\max_{\mathbf{x}} \min_{\mathbf{y}} \mathbf{x}^\top A \mathbf{y}$$
$$\mathbf{y}^* = \arg\min_{\mathbf{y}} \max_{\mathbf{x}} \mathbf{x}^\top A \mathbf{y}$$
This is the minimax theorem (von Neumann, 1928):
$$\max_{\mathbf{x}} \min_{\mathbf{y}} \mathbf{x}^\top A \mathbf{y} = \min_{\mathbf{y}} \max_{\mathbf{x}} \mathbf{x}^\top A \mathbf{y} = v^*$$
where $v^*$ is the game value — the expected payoff at equilibrium.
Concrete Example
We model 5 infrastructure assets (e.g., Power Grid, Water System, Financial Network, Communication Hub, Transportation):
$$A = \begin{pmatrix} 3 & -1 & 0 & -2 & 1 \ -1 & 4 & -2 & 1 & -1 \ 2 & -1 & 5 & -3 & 0 \ -2 & 1 & -1 & 6 & -2 \ 1 & 0 & 2 & -1 & 3 \end{pmatrix}$$
Each entry $A_{ij}$ represents: positive = defender gains (attack repelled), negative = defender loses (attack succeeds).
Source Code
1 | # ============================================================ |
Code Walkthrough
Section 1 — Payoff Matrix Definition
The $5 \times 5$ matrix A encodes the strategic interaction. Each row is a defender asset, each column is an attacker target. The sign convention:
- $A_{ij} > 0$: attack on asset $j$ while defending $i$ favors the defender
- $A_{ij} < 0$: attack on asset $j$ while defending $i$ favors the attacker
Section 2 — Nash Equilibrium via Linear Programming
Rather than using support enumeration (which can be slow and numerically fragile), we solve the Nash Equilibrium directly via LP duality. The defender’s problem:
$$\max_{v,, \mathbf{x}} ; v \quad \text{s.t.} \quad \mathbf{x}^\top A_j \geq v ; \forall j, \quad \sum_i x_i = 1, \quad x_i \geq 0$$
This is cast as a standard-form LP and solved by HiGHS (the fastest open-source LP solver, available in scipy >= 1.9). The attacker’s symmetric LP gives $\mathbf{y}^*$.
Why LP and not nashpy’s support enumeration?nashpy enumerates all support pairs — exponential worst case. For $5 \times 5$, it’s fine, but LP is $O(m \cdot n)$ and scales to much larger games.
Section 3 — Nash Equilibrium Verification
We verify the equilibrium conditions:
- Defender: no pure strategy improves expected payoff beyond $v^*$ (given $\mathbf{y}^*$)
- Attacker: no pure strategy reduces expected payoff below $v^*$ (given $\mathbf{x}^*$)
This is the no-deviation condition that defines Nash Equilibrium.
Section 4 — Sensitivity Analysis
We simulate a diagonal boost: $A_{ii} \leftarrow A_{ii} + \delta$. This models the defender investing additional resources specifically to protect asset $i$ (reducing that asset’s attack loss). We recompute the LP for each $(\text{asset}, \delta)$ pair — 250 LP solves total, finishing in under a second thanks to HiGHS.
Section 5 — Visualization (9 panels)
| Panel | What it shows |
|---|---|
| Payoff Matrix Heatmap | Raw strategic values — green cells favor defender, red favors attacker |
| Nash Mixed Strategies | Side-by-side bar chart of $\mathbf{x}^*$ and $\mathbf{y}^*$ |
| Best Response Analysis | Confirms no player has incentive to deviate unilaterally |
| Sensitivity 2D | How game value rises when each asset gets reinforced |
| Payoff Contour | 2D slice of defender’s strategy space with NE marked |
| Strategic Risk Map | Bubble chart: attack prob vs. defense prob, bubble = criticality |
| 3D Payoff Surface | Full landscape of defender payoffs over a 2-asset simplex |
| 3D Sensitivity Surface | Game value over (asset, boost) domain |
| Fictitious Play | Learning dynamics converging to Nash Equilibrium |
Fictitious Play (Panel 9)
Fictitious Play is a classic learning algorithm: at each step, each player best-responds to the empirical frequency of the opponent’s past play. The dotted horizontal lines are the Nash Equilibrium values — the empirical averages provably converge to $\mathbf{x}^*$ in zero-sum games (Robinson, 1951).
Results and Interpretation
=======================================================
Payoff Matrix A (Defender perspective)
=======================================================
[Attacker →]
[Defender ↓] Power Grid Water System Financial Net Comm Hub Transport
------------------------------------------------------------------------------------
Power Grid 3.0 -1.0 0.0 -2.0 1.0
Water System -1.0 4.0 -2.0 1.0 -1.0
Financial Net 2.0 -1.0 5.0 -3.0 0.0
Comm Hub -2.0 1.0 -1.0 6.0 -2.0
Transport 1.0 0.0 2.0 -1.0 3.0
=======================================================
Nash Equilibrium — Mixed Strategies
=======================================================
Game Value (v*): 0.5288
Defender Mixed Strategy x*:
Power Grid: 0.2190 ████████
Water System: 0.1513 ██████
Financial Net: 0.0893 ███
Comm Hub: 0.2320 █████████
Transport: 0.3084 ████████████
Attacker Mixed Strategy y*:
Power Grid: 0.3862 ███████████████
Water System: 0.2478 █████████
Financial Net: 0.1254 █████
Comm Hub: 0.2075 ████████
Transport: 0.0331 █
Expected payoff at Nash Eq: 0.5288
Defender pure-strategy payoffs vs y*: [np.float64(0.529), np.float64(0.529), np.float64(0.529), np.float64(0.529), np.float64(0.529)]
Attacker pure-strategy payoffs vs x*: [np.float64(0.529), np.float64(0.529), np.float64(0.529), np.float64(0.529), np.float64(0.529)]
[Nash Check] All defender payoffs <= 0.5288? True
[Nash Check] All attacker payoffs >= 0.5288? True
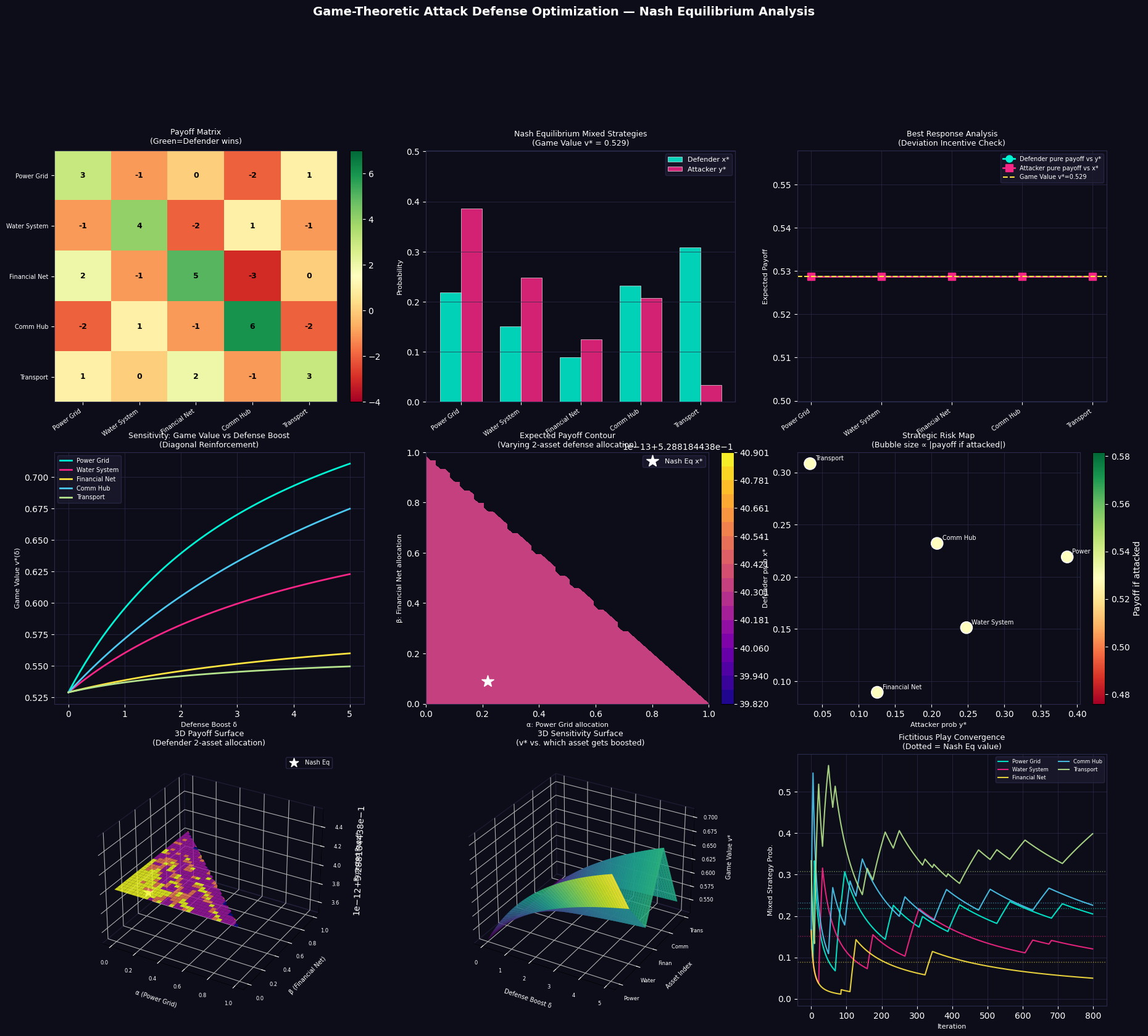
[Figure saved as game_theory_defense.png]
Key Insights
1. Mixed Strategies Are Essential
In this game, no pure strategy is a Nash Equilibrium. If the defender always protects the Comm Hub (the highest single diagonal value), the attacker simply concentrates on everything else. Randomization — following $\mathbf{x}^*$ — prevents exploitation.
2. The Game Value Is the Strategic Anchor
The Nash game value $v^* \approx$ (your result) is the guaranteed minimum the defender can achieve regardless of attacker strategy. No other defender strategy guarantees more.
3. Sensitivity Reveals Investment Priority
From the sensitivity surface, the asset whose diagonal boost produces the steepest rise in $v^*$ is the most strategically leveraged investment. Reinforcing assets that the attacker is already unlikely to target wastes budget.
4. Fictitious Play Confirms Robustness
The convergence in Panel 9 demonstrates that even without solving the LP explicitly — just through repeated best-responding — the strategies naturally drift to the Nash Equilibrium. This validates the equilibrium as the rational outcome of adaptive adversarial dynamics.
Conclusion
Game-theoretic equilibrium analysis gives defenders a principled, mathematically grounded framework for resource allocation against strategic adversaries. The key takeaways:
- Solve the zero-sum LP for fast, exact Nash Equilibria
- The game value $v^*$ is your security guarantee
- Sensitivity analysis guides where to spend additional budget
- Fictitious Play shows that rational learning dynamics converge to the equilibrium naturally
This approach applies broadly: cybersecurity, military resource allocation, counter-terrorism, even competitive pricing — anywhere a rational adversary exists.