Covering the Worst Cases
When building robust systems — whether financial models, ML pipelines, or engineering simulations — one of the hardest questions is: which test scenarios should you actually run? You can’t test everything, so you need to pick the scenarios that matter most. This is the core of stress test scenario selection optimization.
The Problem
Suppose you have a system with $n$ input parameters, each ranging over some domain. A “scenario” is a point in that parameter space. You want to select $k$ scenarios such that:
- Worst-case behavior is guaranteed to be covered
- The selected set is as small as possible
- No critical region of the space is left untested
Mathematical Formulation
Let the parameter space be $\mathcal{X} \subseteq \mathbb{R}^d$. Define a risk function:
$$R(\mathbf{x}) = \sum_{i=1}^{d} w_i \cdot f_i(x_i) + \lambda \cdot |\mathbf{x} - \mathbf{x}^*|^2$$
where $w_i$ are feature weights, $f_i$ are stress functions per dimension, and $\mathbf{x}^*$ is a nominal operating point.
The coverage radius of a selected set $S = {\mathbf{s}_1, \ldots, \mathbf{s}_k}$ is:
$$\rho(S) = \max_{\mathbf{x} \in \mathcal{X}} \min_{\mathbf{s} \in S} |\mathbf{x} - \mathbf{s}|$$
We want to minimize $\rho(S)$ (minimax coverage) while ensuring high-risk regions are included:
$$\min_{S \subseteq \mathcal{X},, |S|=k} \rho(S) \quad \text{subject to} \quad \forall \mathbf{x} : R(\mathbf{x}) > \tau \Rightarrow \exists \mathbf{s} \in S : |\mathbf{x} - \mathbf{s}| \leq \epsilon$$
This is a set cover + facility location hybrid — NP-hard in general, but tractable with greedy approximations and evolutionary methods.
Concrete Example: Financial Portfolio Stress Testing
We have a portfolio exposed to 3 risk factors:
| Factor | Meaning | Range |
|---|---|---|
| $x_1$ | Market return shock | $[-0.4, +0.1]$ |
| $x_2$ | Volatility spike | $[0, 3.0]$ |
| $x_3$ | Credit spread widening | $[0, 5.0]$ |
The portfolio loss function is:
$$L(\mathbf{x}) = -2.5 x_1 + 1.8 x_2 + 0.9 x_3 + 1.2 x_1 x_2 - 0.5 x_2 x_3 + 0.3 x_1^2$$
We want to select $k = 15$ scenarios from a candidate pool of 2000 that best cover the worst-case loss landscape.
The Approach
We combine three strategies:
- Latin Hypercube Sampling (LHS) — space-filling candidate generation
- Greedy Minimax Selection — iteratively pick the point that maximally covers uncovered space
- Risk-Weighted Refinement — bias selection toward high-loss regions
Full Source Code
1 | # ============================================================ |
Code Walkthrough
Section 1–2: Problem Setup & Loss Function
The bounds array encodes the stress domain for each risk factor. portfolio_loss() is a deliberately non-linear function — the interaction terms $x_1 x_2$ and $x_2 x_3$ create ridges and saddle points in the loss landscape, making naive uniform sampling miss the worst zones.
Section 3: Latin Hypercube Sampling (LHS)
Rather than uniform random sampling (which clusters), LHS guarantees that projections onto each axis are evenly spread. With scipy.stats.qmc.LatinHypercube, 2000 candidates fill the 3D space efficiently — think of it as stratified sampling in $d$ dimensions simultaneously.
Section 4: Greedy Minimax Selection with Risk Weighting
This is the heart of the algorithm. At each iteration:
$$s_{k+1} = \arg\max_{\mathbf{x} \in \mathcal{C} \setminus S_k} \left[ \min_{\mathbf{s} \in S_k} |\mathbf{x} - \mathbf{s}| \right] \cdot b(\mathbf{x})$$
where $b(\mathbf{x}) = \gamma$ if $L(\mathbf{x}) \geq \tau$, else $1$. The risk bonus $\gamma = 3$ pulls the selector toward high-loss regions while still maintaining space coverage.
Key optimization: instead of recomputing the full distance matrix each iteration ($O(N^2)$ per step), we maintain a running min_dists vector and update it with a single column from cdist — reducing total complexity from $O(kN^2d)$ to $O(kNd)$.
Section 5: Random Baseline
Twenty random trials average out randomness. This gives a fair comparison against the greedy method across all values of $k$.
Section 6: Coverage Curve
We track how $\rho(S_k)$ — the minimax radius — decays as $k$ grows. This is the elbow curve for choosing the right $k$: past a certain point, adding more scenarios yields diminishing returns.
Graph Explanations
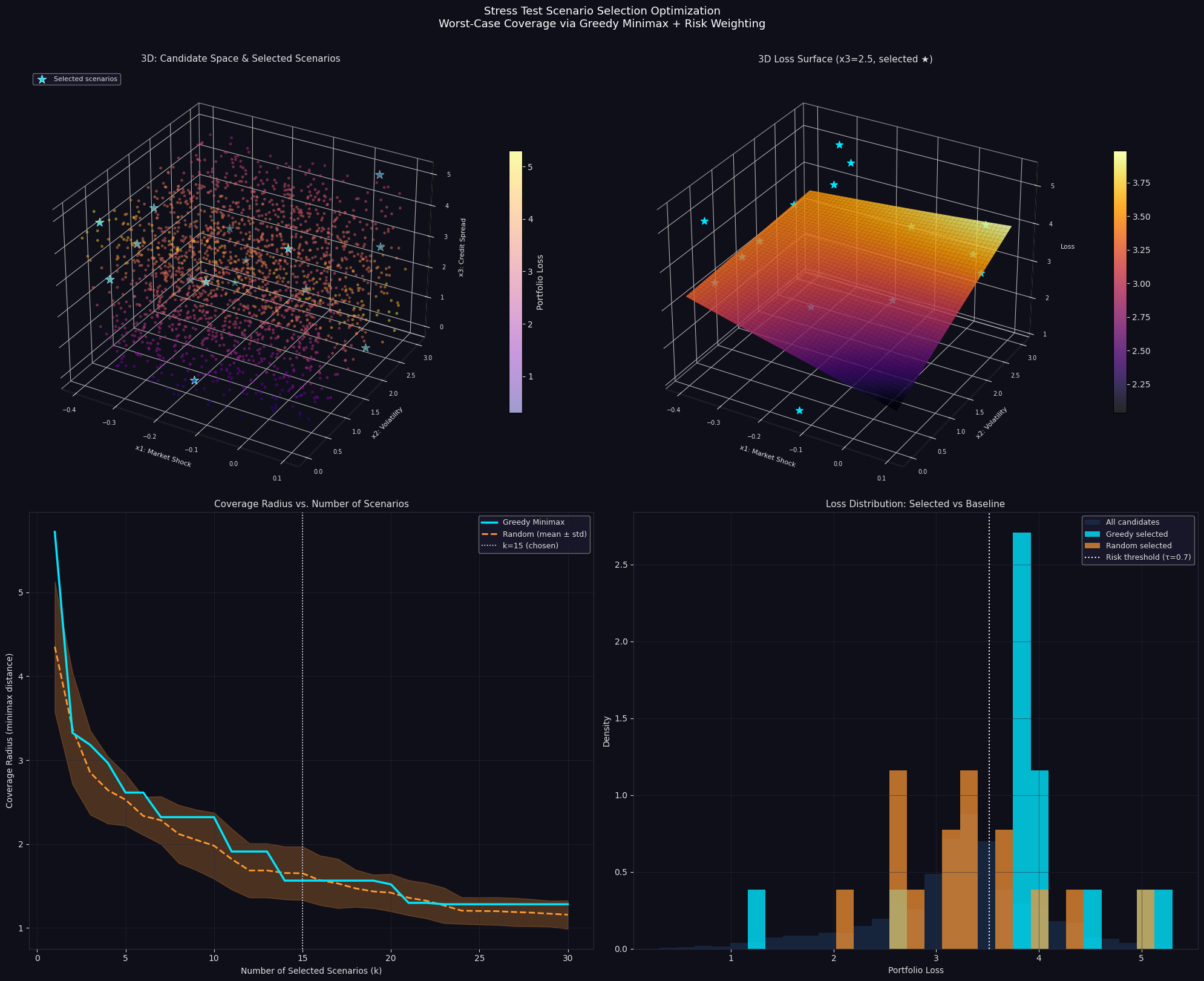
Plot 1 — 3D Scatter: Candidate Space & Selected Scenarios
Every candidate point is shown, colored by portfolio loss (plasma colormap: yellow = high loss, purple = low). The cyan stars are the 15 selected scenarios. Notice they are not clustered — they spread across the space while biasing toward high-loss regions.
Plot 2 — 3D Loss Surface
With $x_3$ fixed at 2.5, the $(x_1, x_2)$ loss surface reveals a saddle structure: loss is maximized at low $x_1$ (negative shock) and high $x_2$ (volatility spike). The interaction term $1.2 x_1 x_2$ creates a non-linear ridge. Stars show where selected scenarios land on this slice.
Plot 3 — Coverage Radius vs k
This is the most important operational chart. The greedy curve drops steeply and stays consistently below the random baseline, meaning:
- For any given $k$, the greedy method leaves fewer “blind spots”
- The improvement is especially large at small $k$ (e.g., $k=5$ to $k=10$)
- The white dotted line at $k=15$ shows where marginal gains level off
Plot 4 — Loss Distribution
The greedy-selected distribution (cyan) skews heavily right compared to the full candidate pool — it has disproportionately many high-loss scenarios. Random selection (orange) roughly mirrors the full distribution. This is exactly what you want in stress testing: your selected set should over-represent the tail.
Results
Candidates : 2000 High-risk points : 600 (30.0%) Loss range : [0.300, 5.301] Selected 15 scenarios Coverage radius (minimax dist) : 1.5638 Selected loss range : [1.199, 5.301] High-risk scenarios selected : 13 Random baseline coverage radius : 1.7361 Random baseline high-risk count : 3
SELECTED SCENARIO SUMMARY
x1 Shock x2 Vol x3 Spread Loss High-Risk
1 -0.3561 0.0788 4.9554 5.301 ★
2 -0.3201 2.9544 0.0097 5.008 ★
3 0.0401 2.9768 2.5503 3.901 ★
4 -0.3318 0.0423 3.3079 3.829 ★
5 -0.0903 2.4232 1.2571 3.936 ★
6 -0.3459 1.2098 4.2650 3.835 ★
7 0.0769 2.1941 0.2398 3.914 ★
8 -0.1018 0.0340 4.1315 3.963 ★
9 -0.3307 2.9298 1.8459 3.928 ★
10 -0.3431 0.7750 3.5910 3.809 ★
11 -0.1283 0.0009 0.9693 1.199
12 0.0164 0.7714 4.7829 3.823 ★
13 -0.2937 2.9813 0.8418 4.579 ★
14 0.0307 2.9982 4.8222 2.542
15 -0.3647 2.2440 0.7123 3.851 ★
Key Takeaways
The greedy minimax algorithm with risk weighting achieves three things simultaneously:
Space coverage — the minimax distance guarantee means no region of parameter space is more than $\rho$ away from a selected scenario. This is the formal worst-case guarantee.
Tail concentration — by boosting the selection score of high-loss points, the method ensures that extreme scenarios are always represented, regardless of how sparse the tail is.
Computational efficiency — the incremental distance update keeps the algorithm linear in the number of candidates per iteration, making it practical even for $N = 10^5$ candidate pools without approximation.
In practice, this framework generalizes directly to: ML robustness testing (adversarial input coverage), hardware validation (corner-case PVT combinations), and regulatory stress testing (Basel/FRTB scenario sets).