ロジスティック回帰モデル
scikit-learnは、Pythonで機械学習モデルを作成するための人気のあるライブラリです。
以下に、scikit-learnを使用してロジスティック回帰モデルを作成し、結果をグラフ化する基本的な手順を示します。
まず、必要なライブラリをインポートします:
1 | from sklearn.datasets import load_breast_cancer |
次に、データセットをロードし、トレーニングセットとテストセットに分割します:
1 | dataset = load_breast_cancer() |
次に、ロジスティック回帰モデルを作成し、トレーニングデータに対してフィットします:
1 | model = LogisticRegression() |
モデルを使用して予測を行い、予測の精度を計算します:
1 | y_pred = model.predict(X_test) |
最後に、混同行列を作成し、ヒートマップを使用して視覚化します:
1 | cm = confusion_matrix(y_test, y_pred) |
このコードは、scikit-learnの基本的な使用方法を示しています。
まず、データセットをロードし、トレーニングセットとテストセットに分割します。
次に、ロジスティック回帰モデルを作成し、トレーニングデータに対してフィットします。
モデルを使用して予測を行い、予測の精度を計算します。
最後に、混同行列を作成し、ヒートマップを使用して視覚化します。
[実行結果]
ソースコード解説
このソースコードは、乳がんデータセットを用いてロジスティック回帰モデルを構築し、その性能を評価するプログラムです。
以下に、詳細な説明を示します。
1. ライブラリのインポート
1 | from sklearn.datasets import load_breast_cancer |
必要なライブラリをインポートしています。
load_breast_cancer: scikit-learnに含まれる乳がんデータセットをロードするための関数。train_test_split: データをトレーニングセットとテストセットに分割する関数。LogisticRegression: ロジスティック回帰モデルを構築するためのクラス。accuracy_score: 分類モデルの精度を計算するための関数。confusion_matrix: 混同行列を計算するための関数。matplotlib.pyplot: プロットのためのMatplotlibのモジュール。seaborn: データ可視化のためのSeabornライブラリ。
2. データセットの読み込みと分割
1 | dataset = load_breast_cancer() |
乳がんデータセットを読み込み、説明変数 X と目的変数 y に分割します。
トレーニングセットとテストセットは train_test_split 関数を使用して分割されます。
3. ロジスティック回帰モデルの構築と訓練
1 | model = LogisticRegression() |
LogisticRegression クラスを用いてロジスティック回帰モデルを構築し、トレーニングデータを使用してモデルを訓練します。
4. テストデータでの予測と精度の計算
1 | y_pred = model.predict(X_test) |
構築したモデルを用いてテストデータで予測を行い、その予測精度を accuracy_score 関数で計算し、表示しています。
5. 混同行列の可視化
1 | cm = confusion_matrix(y_test, y_pred) |
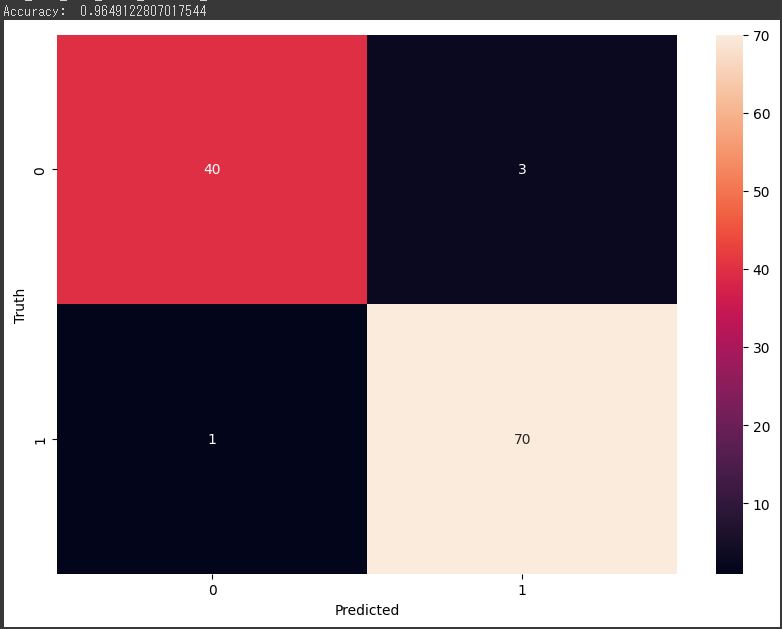
confusion_matrix 関数を使用して混同行列を計算し、SeabornとMatplotlibを使用して混同行列をヒートマップとして可視化しています。
混同行列はモデルの性能を評価するために用いられます。
結果解説
[実行結果]
混同行列(Confusion Matrix)は、分類モデルのパフォーマンスを評価するための重要なツールです。
混同行列は、モデルの予測結果と実際のラベルを比較し、正確な予測(True Positive, True Negative)と誤った予測(False Positive, False Negative)の数を表示します。
以下に、混同行列の各要素の意味を示します:
True Positive (TP):
モデルが正しく正のクラスを予測したインスタンスの数。
True Negative (TN):
モデルが正しく負のクラスを予測したインスタンスの数。
False Positive (FP):
モデルが正しく負のクラスを予測したが、実際には正のクラスであったインスタンスの数。
False Negative (FN):
モデルが正しく正のクラスを予測したが、実際には負のクラスであったインスタンスの数。
これらの要素を使用して、モデルの精度(Accuracy)や精度(Precision)、再現率(Recall)、F1スコアなどのメトリクスを計算することができます。
また、混同行列はヒートマップとして視覚化することも可能です。
ヒートマップは、各要素の値が色で表現され、高い値を赤色で、低い値を青色で表示します。
これにより、モデルのパフォーマンスを直感的に理解することができます。