
アンサンブル学習
アンサンブル学習の一つであるランダムフォレストを例に取り、scikit-learnを使って解説します。
ランダムフォレストは、複数の決定木を組み合わせて予測精度を向上させる手法です。
まず、必要なライブラリをインポートします。
1 | import numpy as np |
次に、データセットを訓練データとテストデータに分割します。
make_classification関数を使用して、仮想的な分類データセットを生成します。
ここでは、n_samples=1000でサンプル数を指定し、n_features=4で特徴量の数を指定しています。
n_informative=2は、実際に予測に寄与する特徴量の数を指定し、n_redundant=0で冗長な特徴量の数を指定しています。
random_state=0でデータの乱数シードを固定し、shuffle=Falseでデータをシャッフルしないようにします。
1 | X, y = make_classification(n_samples=1000, n_features=4, n_informative=2, n_redundant=0, random_state=0, shuffle=False) |
ランダムフォレストのモデルを作成し、訓練データで学習させます。
train_test_split関数を使用してデータセットを訓練データとテストデータに分割します。
ここでは、訓練データが80%、テストデータが20%になるように分割しています。
1 | X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) |
ランダムフォレスト分類器(RandomForestClassifier)を作成し、訓練データで学習させます。
max_depth=2でツリーの深さを2に制限しています。
1 | clf = RandomForestClassifier(max_depth=2, random_state=0) |
テストデータを使用して予測を行い、予測の正確さを評価します。
accuracy_score関数を使用して、実際のラベル(y_test)と予測されたラベル(y_pred)の一致率を計算し、表示します。
1 | y_pred = clf.predict(X_test) |
最後に、特徴量の重要度をグラフ化します。
ランダムフォレストモデルによって計算された特徴量の重要度を取得し、グラフ化して表示します。
importancesには各特徴量の重要度が格納され、indicesは重要度の降順で特徴量のインデックスが格納されます。
グラフはバー(縦棒)で表示され、各バーの高さは特徴量の重要度を表しています。
X軸は特徴量のインデックス、Y軸は重要度を表しています。
1 | importances = clf.feature_importances_ |
[実行結果]
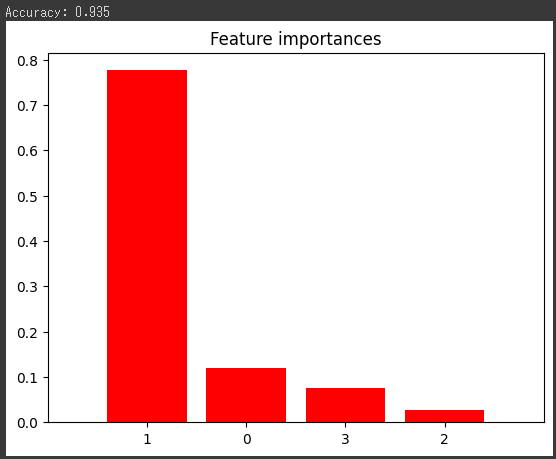
このグラフは、各特徴量がモデルの予測にどれだけ影響を与えているかを示しています。
高いバーは、その特徴量がモデルの予測に大きな影響を与えていることを示しています。
このグラフを通じて、モデルがどの特徴量を重要視しているかを理解することができます。