
クラスタリング
クラスタリング問題の一例として、顧客セグメンテーションを考えてみましょう。
この問題では、顧客の購買行動や属性に基づいて、顧客を異なるグループに分けることを目指します。
ここでは、年齢と年間購入額の2つの特徴を持つ顧客データを考えてみます。
まず、必要なライブラリをインポートします。
1 | import matplotlib.pyplot as pltfrom |
次に、仮想的な顧客データを作成します。
1 | # 仮想的な顧客データを作成 |
このデータをKMeansクラスタリングを用いて分析します。
1 | # KMeansクラスタリング |
最後に、結果をプロットします。
1 | # クラスタリング結果をプロット |
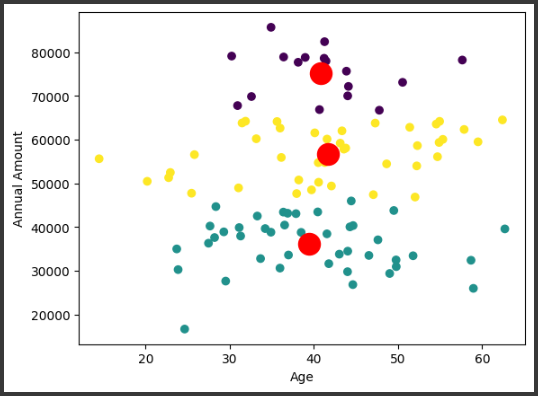
このコードは、年齢と年間購入額に基づいて顧客を3つのクラスタに分けます。
そして、各クラスタの中心点を赤で表示します。これにより、顧客の購買行動のパターンを視覚的に理解することができます。
[実行結果]
このコードは仮想的なデータを使用していますので、実際の問題に適用する際には、適切なデータの前処理やパラメータの調整が必要になることに注意してください。
解説
ソースコードの内容を解説します。
1. 必要なライブラリのインポート:
matplotlib.pyplot: データの可視化のためのライブラリsklearn.cluster.KMeans: K-meansクラスタリングアルゴリズムの実装
2. 仮想的な顧客データの作成:
age: 年齢データを平均40、標準偏差10の正規分布からランダムに生成annual_amount: 年間支出データを平均50000、標準偏差15000の正規分布からランダムに生成X: 年齢と年間支出を結合して特徴行列を作成
3. K-meansクラスタリングの実行:
KMeans(n_clusters=3, random_state=0): クラスタ数を3に設定し、ランダムシードを0に設定してKMeansオブジェクトを作成fit(X): 特徴行列Xに対してクラスタリングを実行し、各サンプルのクラスタラベルを割り当てる
4. クラスタリング結果のプロット:
plt.scatter(X[:, 0], X[:, 1], c=kmeans.labels_): 年齢をx軸、年間支出をy軸にし、各データポイントをクラスタラベルに基づいて散布図としてプロットplt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], s=300, c='red'): クラスタの中心点を赤い色でプロットplt.xlabel('Age')とplt.ylabel('Annual Amount'): x軸とy軸のラベルを設定plt.show(): グラフの表示
このコードは、仮想的な顧客データをK-meansクラスタリングアルゴリズムを使ってクラスタリングし、その結果を散布図として可視化します。
クラスタ数は3と設定されており、年齢と年間支出の2つの特徴量をもとに顧客をクラスタリングします。
クラスタリングの結果、各データポイントが所属するクラスタと、クラスタの中心点がプロットされます。