前回記事までの分類予測では、陽性/陰性という最終的な予測結果のみを見てきましたが、「その予測がどれだけの確信度をもって行われたのか」という情報も重要になります。
確信度
predict_probaメソッドに予測対象データを渡すと、確率の形式で予測結果を出力することができます。
[Google Colaboratory]
1 | pred_proba_train = rf_cls.predict_proba(X_train) |
[実行結果]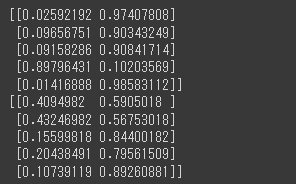
出力された配列には、陽性に分類される確率と陰性に分類される確率がそれぞれ格納されています。
デフォルトでは、50%を上回っているカテゴリを最終的な予測結果とするようになっていますが、このように確率を算出することで60%以上であれば陽性とするなど、新たな閾値を設定することも可能です。
確信度の可視化
領域ごとの確信度を可視化してみます。
[Google Colaboratory]
1 | import numpy as np |
[実行結果]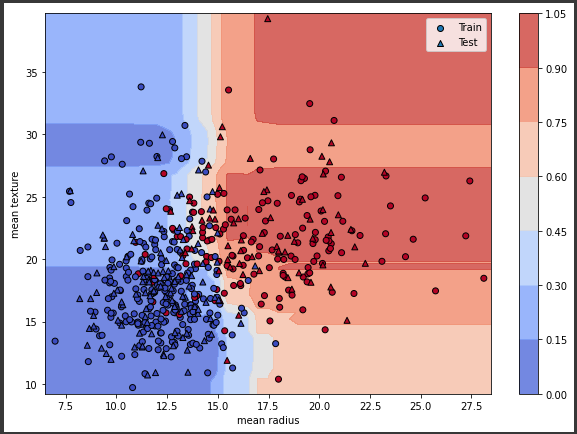
背景のメッシュ部分が陽性に分類される確信度を表しています。
各変数(mean/radius/mean texture)の最小値から最大値の範囲内で、それぞれ0.5刻みでデータを新たに生成し、それぞれのデータを説明変数としてpredict_probaで算出した確信度を可視化しています。
確信度を可視化することで、どの領域で誤分類が起こりやすいかを把握することができます。