ランダムフォレストは、複数の異なる決定木を生成し、予測結果を総合的に判断するアルゴリズムです。
回帰では各決定木から得られた結果の平均を予測値としていましたが、分類では各決定木の結果の多数決で予測値を決定します。
単一の決定木と比較して、モデルの解釈性は劣るものの過学習を抑えられ、精度の向上が期待できます。
ランダムフォレストモデルの構築
ランダムフォレストの分類モデルを構築するためには、scikit-learnのRandomForestClassifierクラスを使います。
前回記事にて実行した決定木モデルの結果と比較するため、max_depthの値は3にします。
[Google Colaboratory]
1 | from sklearn.ensemble import RandomForestClassifier |
ランダムフォレストのようなアンサンブル学習を行うアルゴリズムは、SVMや決定木に比べてハイパーパラメータのチューニングをシビアに行わなくても、ある程度高い精度が出やすいことが特徴となります。
決定境界の可視化
plot_decision_regionsメソッドを使い決定境界を可視化します。
[Google Colaboratory]
1 | plot_decision_regions(np.array(X_train), np.array(y_train), clf=rf_cls) |
[実行結果]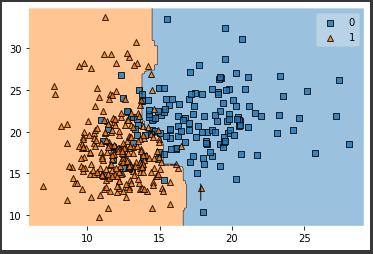
ランダムフォレストでは複数の決定木の結果をもとに分類予測を行うため、単一の決定木と比較して複雑な決定境界が引かれます。