決定木は、回帰問題だけでなく分類問題でもよく使われるアルゴリズムです。
モデルの解釈性が優れていることや、過学習に陥りやすいという特徴があります。
またハイパーパラメータの種類も決定木回帰と共通するものが多いです。
決定木モデルの構築
決定木の分類モデルを構築するためには、scikit-learnのDecisionTreeClassifierクラスを使います。
【参考】決定木の回帰モデルではDecisionTreeRegressorクラスを使いました。
[Google Colaboratory]
1 | from sklearn.tree import DecisionTreeClassifier |
モデルが複雑になるのを避けるため、決定木の層の最大深さ(max_depth)を3に指定しました。
訓練データにはスケーリング前のデータを使用しています。
決定木は単一の説明変数の大小に着目したアルゴリズムであるため、スケーリングの必要がないためです。
決定境界の可視化
plot_decision_regionsメソッドを使い決定境界を可視化します。
[Google Colaboratory]
1 | plot_decision_regions(np.array(X_train), np.array(y_train), clf=tree_cls) |
[実行結果]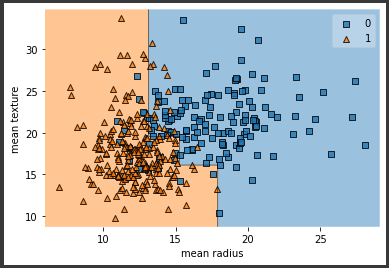
これまで試してきたアルゴリズムとはかなり違う形の決定境界となっています。
どうしてこのような分類になったのかを確認するために、決定木の内容を確認します。
決定木の可視化
決定木を可視化します。
視覚的に分かりやすくするため、ノード内のサンプルが占めるカテゴリの割合(value)に応じて各ノードを色分けしています。
またサンプル数とvalueの値は割合で表示しています。
[Google Colaboratory]
1 | from sklearn import tree |
[実行結果]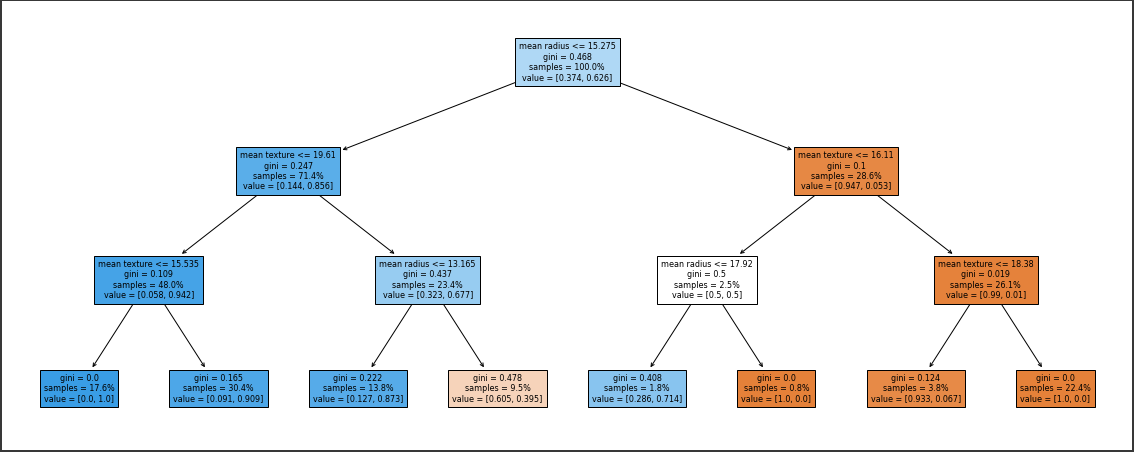
決定木の各条件を上から順に散布図に当てはめていくと、先ほど可視化したものと同じようにカクカクした決定境界となります。
このように決定木を可視化することでどのような条件でどのカテゴリに分類されるのかが説明可能になります。