K近傍法は、周辺にあるK個の訓練データがどちらに分類されているか多数決で分類するアルゴリズムです。
これまでのアルゴリズムのように計算をして傾向を導き出すのではなく、単純に訓練データを丸暗記している点が大きく異なります。
K近傍法のような学習のアプローチを怠惰学習と呼ぶこともあります。
K近傍法モデルの構築
K近傍法モデルを構築するためには、scikit-learnのKNeighborsClassifierクラスを使用します。(2行目)
引数の意味は下記の通りです。
- n_neighbors
予測時に見る訓練データの数。 - p
距離の指標。
1がユークリッド距離、2がマンハッタン距離の指定となります。
[Google Colaboratory]
1 | from sklearn.neighbors import KNeighborsClassifier |
データセットは、これまでと同じ「乳がんの診断データ」を使用しています。
複雑な計算を行っていないため、学習プロセスは高速に完了します。
決定境界の可視化
plot_decision_regionsメソッドを使い決定境界を可視化します。
[Google Colaboratory]
1 | plot_decision_regions(np.array(X_train_scaled), np.array(y_train), clf=kn_cls) |
[実行結果]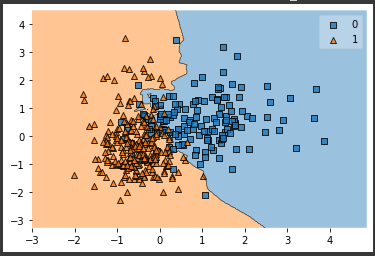
K近傍法では、暗記した訓練データを予測時に参照するという特徴から、学習は高速で終わりますが、予測には時間がかかります。
また訓練データ数が多くなるほど、予測に要する時間が長くなる傾向があります。
計算コストが高くなりやすい一方で、モデルの解釈が容易でありどのようなデータセットにも比較的柔軟に対応できるという長所があります。