モデル構築の下準備として、データの前処理を行います。
目的変数と説明変数に分割
まずデータを説明変数 X と目的変数 y に分けます。
[Google Colaboratory]
1 | X= tg_df[["mean radius","mean texture"]] |
[実行結果]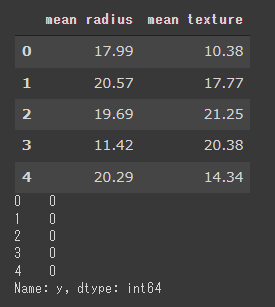
訓練データとテストデータに分割
次に、データを訓練データ(70%)とテストデータ(30%)に分割します。
[Google Colaboratory]
1 | from sklearn.model_selection import train_test_split |
[実行結果]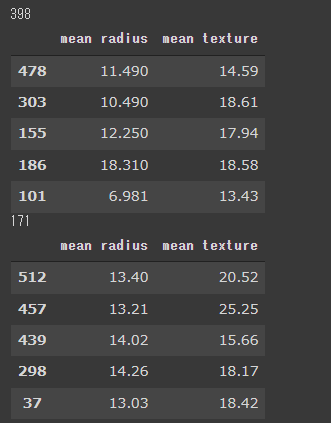
スケーリング
最後に、データの尺度をそろえるためスケーリングを行います。
[Google Colaboratory]
1 | from sklearn.preprocessing import StandardScaler |
[実行結果]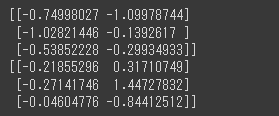
次回は、ロジスティック回帰モデルの構築を行います。