今回から、教師あり学習の1つである分類を実行していきます。
分類はデータがどのカテゴリに分類されているかを予測します。
データの読み込み
分類の問題を解くのに適した乳がん診断データを読み込みます。
悪性か良性かを目的変数として、それに寄与する検査データが説明変数として用意されているデータになります。
[Google Colaboratory]
1 | from sklearn.datasets import load_breast_cancer |
読み込んだデータをデータフレームに格納します。
またデータ件数やカラム数を出力します。
[Google Colaboratory]
1 | import pandas as pd |
[実行結果]
データセットには31列569行のデータがあることが確認できました。
代表値
今回は説明変数としてmean radiusとmean textureの2つのみを使用します。
describeメソッドを使って、データの代表値を確認します。
[Google Colaboratory]
1 | tg_df = df[["mean radius","mean texture","y"]] |
[実行結果]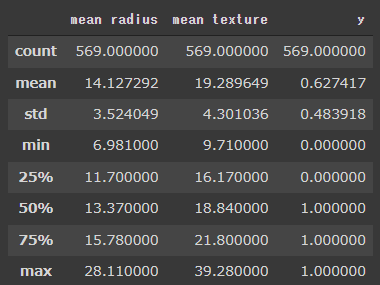
describeメソッドでは欠損値を除外して代表値を算出します。
各変数のcountとデータフレームの行数(569行)が一致しているので、このデータセットに欠損値はないことになります。
相関係数
使用する変数の相関を確認します。
[Google Colaboratory]
1 | tg_df.corr() |
[実行結果]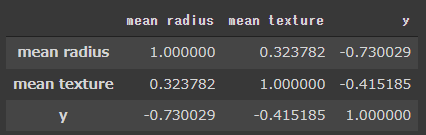
目的変数と相関も程よく強く、説明変数同士の相関が強すぎることもないので説明変数として問題ないようです。
カテゴリ数
何種類のカテゴリがあるかを確認します。
[Google Colaboratory]
1 | print(tg_df["y"].unique()) |
[実行結果]
目的変数のユニークな値より、2種類のカテゴリがあることが確認できました。
0が悪性、1が良性のデータとなります。
カテゴリ比率
各カテゴリの比率を確認します。
[Google Colaboratory]
1 | print(len(df.loc[tg_df["y"]==0])) |
[実行結果]
カテゴリ比率に大きな隔たりはないようです。
カテゴリの比率に大きな隔たりがあるデータは不均衡なデータと呼ばれ、モデルの評価や学習に影響がでるので注意が必要です。
データの可視化
最後に、データをプロットしてカテゴリごとの散布状態を確認します。
[Google Colaboratory]
1 | import matplotlib.pyplot as plt |
[実行結果]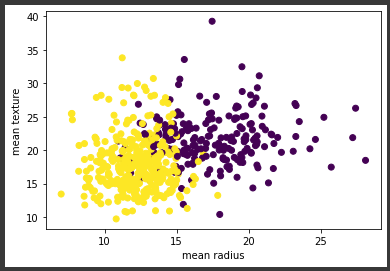
次回からは、この2カテゴリに分類されたデータから機械学習を使って分類の傾向を調べます。