単回帰モデルの構築を行います。
モデルとは、入力されたデータを何らかの基準に基づいて計算し結果を出力する仕組みのことです。
機械学習では訓練データの傾向から、この何らかの基準にあたる部分を定義します。
こうすることにより説明変数を入力すれば、予測値を出力する機械学習モデルが完成します。
データ分割
まずはデータを説明変数と目的変数に分割します。
前回記事で予告した通り、説明変数にはRM(平均部屋数)を使用します。
[Google Colaboratory]
1 | X = df[["RM"]] |
[実行結果]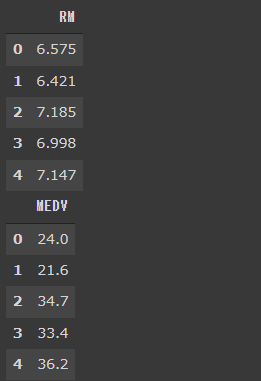
次に、説明変数を訓練データとテストデータに分割します。
- 訓練データ
学習に使用するデータ - テストデータ
訓練データの学習によって構築されたモデルの精度評価を行うデータ
訓練データとテストデータは、7:3の割合で分割します。(3行目のtest_size=0.3で指定)
test_sizeは小数で指定すると割合、整数で指定すると個数として認識されます。
random_stateには再現性を確保するため0を指定しています。
[Google Colaboratory]
1 | from sklearn.model_selection import train_test_split |
[実行結果]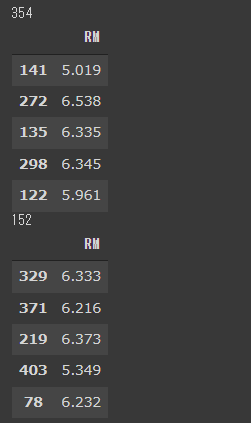
訓練データ数が354、テストデータ数が152に分割されました。
単回帰モデルの構築
訓練データとテストデータの準備が完了しましたので、単回帰モデルの構築を行います。
scikit-learnのLinearRegressionクラスを使用します。
[Google Colaboratory]
1 | from sklearn.linear_model import LinearRegression |
3行目のfitメソッドで訓練データを学習させています。
これでモデルの構築はあっさり完了です。
モデルを使った予測
構築した単回帰モデルを使って予測結果を出力します。
predictメソッドに説明変数となるデータを渡すことで、予測を行うことができます。
[Google Colaboratory]
1 | y_train_pred = simple_reg.predict(X_train) |
[実行結果]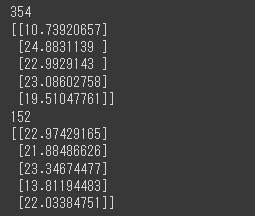
予測結果が出力されました。
次回は、今回構築した単回帰モデルがどれくらいの精度で予測できているのかを評価します。