混合ガウスモデル(GMM:Gaussian Mixture Model)でのクラスタリングを試してみます。
GMMは各データが、どのガウス分布に所属している確率が最も高いかを求めてラベリングを行います。
GMMでクラスタリング
データは前前回使用したワインの分類データセットを使います。(前前回記事を参照)
比較のため、最初にk-meansのクラスタリング結果を可視化し(1~5行目)、その後にGMMでクラスタリングを行ってから同じく可視化しています(7~15行目)。
GMMモデルはmixture.GaussianMixture関数で作成し、クラスタ数(n_components)には3を指定しています。(8行目)
[Google Colaboratory]
1 | plt.figure(figsize=(10,3)) |
[実行結果]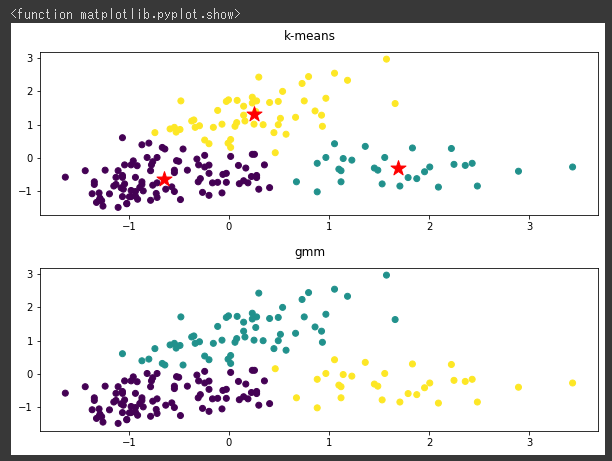
k-meansとGMMでのクラスタリング結果はほとんど同じように見えます。
ただk-meansでは同心円状での分類であり、GMMは傾いた楕円形の分類であるために多少の違いがあるようです。
またGMMではガウス分布を仮定するので、各データがどのクラスタに所属するのかという確率を求めることができます。