3×3の迷路をランダムに探索してゴールを目指すエージェントを実装します。
S0地点がスタート位置で、S8地点がゴール位置になります。
使用するパッケージをインポートします。
1 | # 使用するパッケージの宣言 |
次に迷路の初期状態を描画します。
1 | # 初期位置での迷路の様子 |
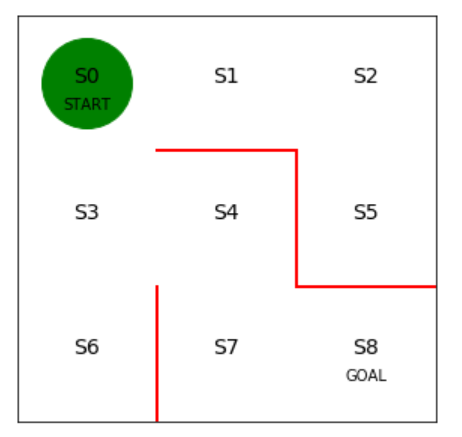
エージェントを実装します。エージェントは緑色の丸で表示します。
エージェントがどのように行動するのかを決めたルールは方策(Policy)といいます。
初期の方策を決定するパラメータtheta_0を設定します。
行は状態0~7を表し、列は上、右、下、左へ行動できるかどうかを表します。
状態8はゴールなので方策の定義は不要です。
1 | # 初期の方策を決定するパラメータtheta_0を設定 |
パラメータtheta_0を割合に変換して確率にします。
1 | # 方策パラメータthetaを行動方策piに変換する関数の定義 |
初期の方策pi_0を算出します。
1 | # 初期の方策pi_0を求める |
初期の方策pi_0を表示します。
1 | # 初期の方策pi_0を表示 |

続いて、方策pi_0に従ってエージェントを行動させます。
1step移動後の状態sを求める関数get_next_sを定義します。
迷路の位置は0~8の番号で定義しているため、上に移動する場合は数字を3小さくすればよいことになります。
1 | # 1step移動後の状態sを求める関数を定義 |
迷路内をエージェントがゴールするまで移動させる関数を定義します。
ゴールにたどり着くまでwhile文で移動し続け、状態の軌跡をstate_historyに格納しています。
1 | # 迷路内をエージェントがゴールするまで移動させる関数の定義 |
方策pi_0に従ってエージェントを移動させます。
1 | # 迷路内をゴールを目指して、移動 |
ゴールするまでの移動の軌跡と、合計何ステップかかったかを確認します。
1 | print(state_history) |
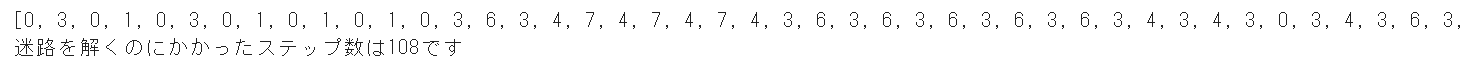
ランダムに移動しているので、状態の軌跡は実行するたびに変わります。
迷路内をエージェントが移動する様子を動画にしてみます。
1 | # エージェントの移動の様子を可視化します |
動画を見ると何回もさまよいながら最終的にはゴールにたどり着く様子を見ることができます。
(Google Colaboratoryで動作確認しています。)
参考
つくりながら学ぶ!深層強化学習 サポートページ