畳み込みニューラルネットワークで写真の画像分類を行います。
データセットはCIFAR-10を使用します。10個に分類された画像と正解ラベルを集めたデータセットで、訓練データ50000件、テストデータ10000件が含まれています。
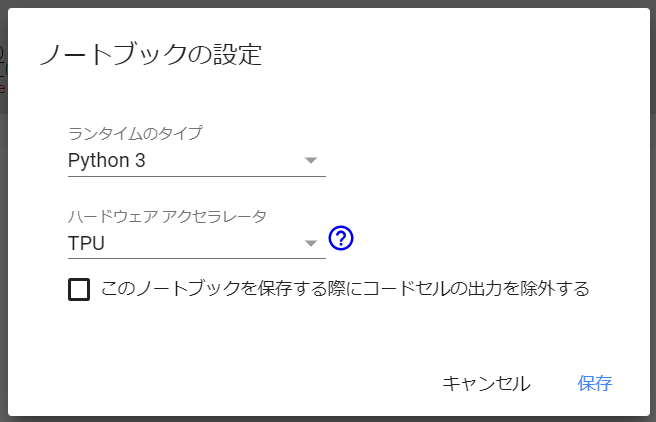
まずGoogle Colaboratoryのランタイムのハードウェアアクセラレータを「TPU」に設定します。
次にtensorflowのバージョンを1.13.1にします。
1 2 !pip uninstall tensorflow -y !pip install tensorflow==1.13.1
インストール後にランタイムをリスタートする必要があります。
1 2 3 4 5 6 7 8 9 from tensorflow.keras.datasets import cifar10from tensorflow.keras.layers import Activation, Dense, Dropout, Conv2D, Flatten, MaxPool2Dfrom tensorflow.keras.models import Sequential, load_modelfrom tensorflow.keras.optimizers import Adamfrom tensorflow.keras.utils import to_categoricalimport numpy as npimport matplotlib.pyplot as plt%matplotlib inline
データセットの準備を行います。
データセットの配列は下記のようになります。
配列
説明
train_images
訓練画像の配列
train_labels
訓練ラベルの配列
test_images
テスト画像の配列
test_labels
テストラベルの配列
1 2 (train_images, train_labels), (test_images, test_labels) = cifar10.load_data()
データセットのシェイプを確認します、
1 2 3 4 5 print (train_images.shape)print (train_labels.shape)print (test_images.shape)print (test_labels.shape)
1 2 3 4 5 for i in range (10 ): plt.subplot(2 , 5 , i+1 ) plt.imshow(train_images[i]) plt.show()
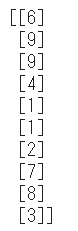
1 2 print (train_labels[0 :10 ])
ラベルの意味は下記の通りです。
ID
説明
0
airplane(飛行機)
1
automobile(自動車)
2
bird(鳥)
3
cat(猫)
4
deer(鹿)
5
dog(犬)
6
frog(カエル)
7
horse(馬)
8
ship(船)
9
truck(トラック)
データセットの前処理と確認を行います。
訓練画像とテスト画像の正規化を行います。画像のRGBは「0~255」なので255で割って「0.0~1.0」に変換します。
1 2 3 4 5 6 7 train_images = train_images.astype('float32' )/255.0 test_images = test_images.astype('float32' )/255.0 print (train_images.shape)print (test_images.shape)

訓練ラベルとテストラベルをone-hot表現に変換します。
1 2 3 4 5 6 7 train_labels = to_categorical(train_labels, 10 ) test_labels = to_categorical(test_labels, 10 ) print (train_labels.shape)print (test_labels.shape)
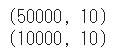
畳み込みニューラルネットワークのモデルを作成します。
モデルのネットワーク構造は下記の通りです。
特徴の抽出を行う。(畳み込みブロック)
(1回目)畳み込み層→畳み込み層→プーリング層→Dropout
(2回目)畳み込み層→畳み込み層→プーリング層→Dropout
1次元に変換する。(Flatten)
分類を行う。
全結合層
Dropout
全結合層
利用するクラスは次の通りです。
クラス
説明
Conv2D
畳み込み層。引数はカーネル数、カーネルサイズ、活性化関数、パティング。
MaxPool2D
プーリング層(Maxプーリング)。引数はプーリング適用領域。
Dense
全結合層。引数はユニット数と活性化関数。
Dropout
ドロップアウト。引数は無効にする割合。
Flatten
層の入出力を1次元に変換。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 model = Sequential() model.add(Conv2D(32 , (3 , 3 ), activation='relu' , padding='same' , input_shape=(32 , 32 , 3 ))) model.add(Conv2D(32 , (3 , 3 ), activation='relu' , padding='same' )) model.add(MaxPool2D(pool_size=(2 , 2 ))) model.add(Dropout(0.25 )) model.add(Conv2D(64 , (3 , 3 ), activation='relu' , padding='same' )) model.add(Conv2D(64 , (3 , 3 ), activation='relu' , padding='same' )) model.add(MaxPool2D(pool_size=(2 , 2 ))) model.add(Dropout(0.25 )) model.add(Flatten()) model.add(Dense(512 , activation='relu' )) model.add(Dropout(0.5 )) model.add(Dense(10 , activation='softmax' ))
TPUモデルへの変換を行います。
1 2 3 4 5 6 7 8 9 import tensorflow as tfimport ostpu_model = tf.contrib.tpu.keras_to_tpu_model( model, strategy=tf.contrib.tpu.TPUDistributionStrategy( tf.contrib.cluster_resolver.TPUClusterResolver(tpu='grpc://' + os.environ['COLAB_TPU_ADDR' ]) ) )
畳み込みニューラルネットワークモデルのコンパイルを行います。
1 2 tpu_model.compile (loss='categorical_crossentropy' , optimizer=Adam(lr=0.001 ), metrics=['acc' ])
訓練画像と訓練ラベルの配列をモデルに渡して学習を開始します。
1 2 3 history = tpu_model.fit(train_images, train_labels, batch_size=128 , epochs=20 , validation_split=0.1 )
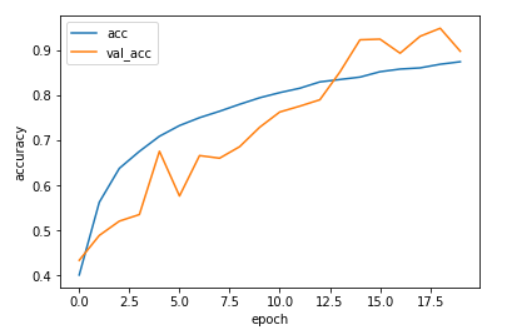
1 2 3 4 5 6 7 plt.plot(history.history['acc' ], label='acc' ) plt.plot(history.history['val_acc' ], label='val_acc' ) plt.ylabel('accuracy' ) plt.xlabel('epoch' ) plt.legend(loc='best' ) plt.show()
1 2 3 test_loss, test_acc = tpu_model.evaluate(test_images, test_labels) print ('loss: {:.3f}\nacc: {:.3f}' .format (test_loss, test_acc ))
1 2 3 4 5 6 7 8 9 10 11 12 for i in range (10 ): plt.subplot(2 , 5 , i+1 ) plt.imshow(test_images[i]) plt.show() test_predictions = tpu_model.predict(test_images[0 :16 ]) test_predictions = np.argmax(test_predictions, axis=1 )[0 :10 ] labels = ['airplane' , 'automobile' , 'bird' , 'cat' , 'deer' , 'dog' , 'frog' , 'horse' , 'ship' , 'truck' ] print ([labels[n] for n in test_predictions])
画像と推測結果を比較すると正解率が90%であることが分かります。
(Google Colaboratory で動作確認しています。)
参考
AlphaZero 深層学習・強化学習・探索 人工知能プログラミング実践入門 サポートページ