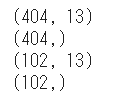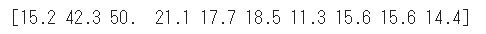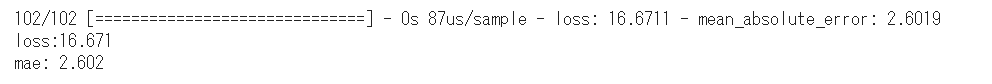ニューラルネットワークで数値データの予測を行う推論モデルを作成します。
まず回帰に必要なパッケージをインポートします。
1 2 3 4 5 6 7 8 9 10 from tensorflow.keras.datasets import boston_housingfrom tensorflow.keras.layers import Activation, Dense, Dropoutfrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.callbacks import EarlyStoppingfrom tensorflow.keras.optimizers import Adamimport pandas as pdimport numpy as npimport matplotlib.pyplot as plt%matplotlib inline
データセットの準備を行います。
データセットの配列は下記のようになります。
配列
説明
train_data
訓練データの配列
train_labels
訓練ラベルの配列
test_data
テストデータの配列
test_labels
テストラベルの配列
データ型はNumpyのndarrayになります。この配列型を使うと高速な配列演算が可能になります。
1 2 (train_data, train_labels), (test_data, test_labels) = boston_housing.load_data()
データセットのシェイプを確認します。
1 2 3 4 5 print (train_data.shape)print (train_labels.shape)print (test_data.shape)print (test_labels.shape)
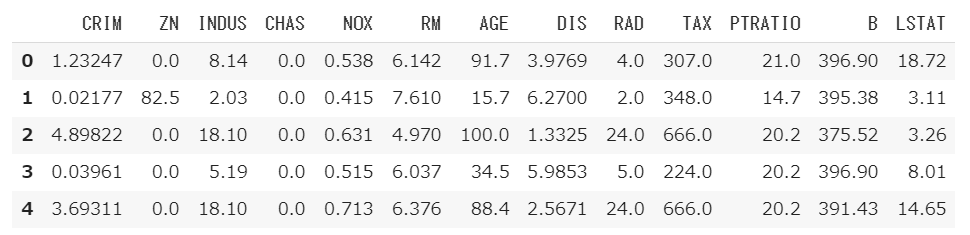
先頭10件の訓練データの確認を行います。
1 2 3 4 column_names = ['CRIM' , 'ZN' , 'INDUS' , 'CHAS' , 'NOX' , 'RM' , 'AGE' , 'DIS' , 'RAD' , 'TAX' , 'PTRATIO' , 'B' , 'LSTAT' ] df = pd.DataFrame(train_data, columns=column_names) df.head()
先頭10件の訓練ラベルの確認を行います。
1 2 print (train_labels[0 :10 ])
訓練データと訓練ラベルのシャッフルを行います。
これは学習時に似たデータを連続して学習すると隔たりが生じてしまうのを防ぐためです。
また正規化を行い、同じ単位で比較しやすくします。
1 2 3 4 5 6 7 8 9 10 order = np.argsort(np.random.random(train_labels.shape)) train_data = train_data[order] train_labels = train_labels[order] mean = train_data.mean(axis=0 ) std = train_data.std(axis=0 ) train_data = (train_data - mean) / std test_data = (test_data - mean) / std
データセットのデータが平均0、分散1になっていることを確認します。
1 2 3 4 column_names = ['CRIM' , 'ZN' , 'INDUS' , 'CHAS' , 'NOX' , 'RM' , 'AGE' , 'DIS' , 'RAD' , 'TAX' , 'PTRATIO' , 'B' , 'LSTAT' ] df = pd.DataFrame(train_data, columns=column_names) df.head()
ニューラルネットワークのモデルを作成します。
1 2 3 4 5 model = Sequential() model.add(Dense(64 , activation='relu' , input_shape=(13 ,))) model.add(Dense(64 , activation='relu' )) model.add(Dense(1 ))
ニューラルネットワークのモデルをコンパイルします。
1 2 model.compile (loss='mse' , optimizer=Adam(lr=0.001 ), metrics=['mae' ])
EarlyStoppingは任意のエポック数を実行したときに改善がないと学習を停止します。
今回は20試行の間に誤差の改善が見られない場合は学習を停止します。
1 2 early_stop = EarlyStopping(monitor='val_loss' , patience=30 )
学習を実行します。callbacksにEarlyStoppingを追加します。
1 2 3 history = model.fit(train_data, train_labels, epochs=500 , validation_split=0.2 , callbacks=[early_stop])
学習時の結果(fit関数の戻り値)には次の情報が含まれています。
情報
説明
loss
訓練データの誤差。0に近いほどよい。
mean_absolute_error
訓練データの平均絶対誤差。0に近いほどよい。
val_loss
検証データの誤差。0に近いほどよい。
val_mean_absolute_error
検証データの平均絶対誤差。0に近いほどよい。
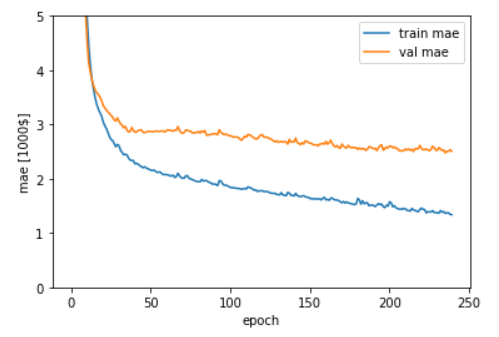
mean_absolute_errorとval_mean_absolute_errorをグラフ表示します。
1 2 3 4 5 6 7 8 plt.plot(history.history['mean_absolute_error' ], label='train mae' ) plt.plot(history.history['val_mean_absolute_error' ], label='val mae' ) plt.xlabel('epoch' ) plt.ylabel('mae [1000$]' ) plt.legend(loc='best' ) plt.ylim([0 ,5 ]) plt.show()
テスト画像とテストラベルの配列をモデルに渡して評価を行います。
1 2 3 test_loss, test_mae = model.evaluate(test_data, test_labels) print ('loss:{:.3f}\nmae: {:.3f}' .format (test_loss, test_mae))
1 2 3 4 5 6 print (np.round (test_labels[0 :10 ]))test_predictions = model.predict(test_data[0 :10 ]).flatten() print (np.round (test_predictions))
(Google Colaboratory で動作確認しています。)
参考
AlphaZero 深層学習・強化学習・探索 人工知能プログラミング実践入門 サポートページ