CIFAR10とういうデータを使って一般物の認識をしてみます。
まずは必要なモジュールをインポートします。
1 | import numpy as np |
共通関数を定義します。
1 | # -------------- # |
一般物体認識のデータセットを読み込みます。
1 | # 一般物体認識のデータセットの読み込み |
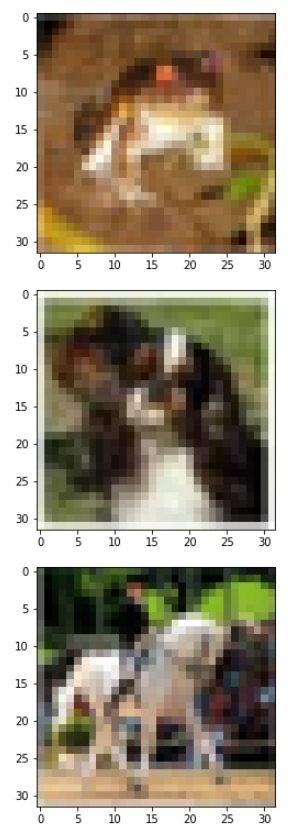
どんなデータがあるかいくつか画像を出力します。
1 | # 試しに画像を出力 |
画像識別の問題に有効な畳み込みニューラルネットワークを設定します。
1 | # 2層畳み込みニューラルネットワークの設定 |
プーリング層を導入した関数を定義します。
1 | # プーリング層の導入 |
GPUを設定します。
1 | # GPUの設定 |
最適化手法を設定します。
1 | # 最適化手法の設定 |
学習の経過を保存する変数を宣言します。
1 | # 学習データ保存エリア |
一度に全部実行するとメモリオーバーになってしまうのでデータセットを分割して実行します。
CIFARのデータは50,000個の訓練データがあるので5,000個ずつを10回に分けて実行します。
1 | # シリアルイテレータの呼び出し |
いつくかのバッチと呼ばれる小さな塊に分けて学習を進める方法をバッチ学習といいます。
特にランダムにデータを選んでニューラルネットワークの最適化を進める方法を確率勾配法といいます。
確率勾配法による最適化を行います。
1 | # 確率勾配法による最適化 |
結果を表示します。
1 | show_graph(result[0], result[1], 'loss function', 'step', 'loss function', 0.0, 4.0) |
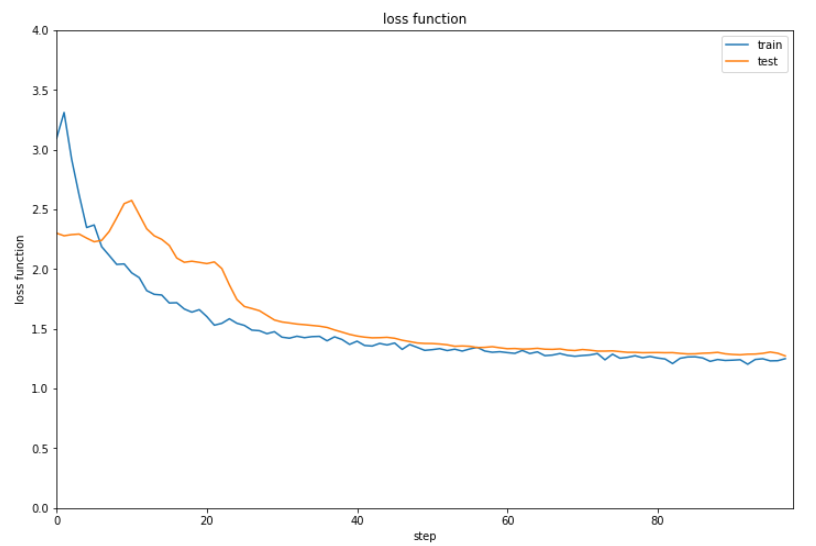
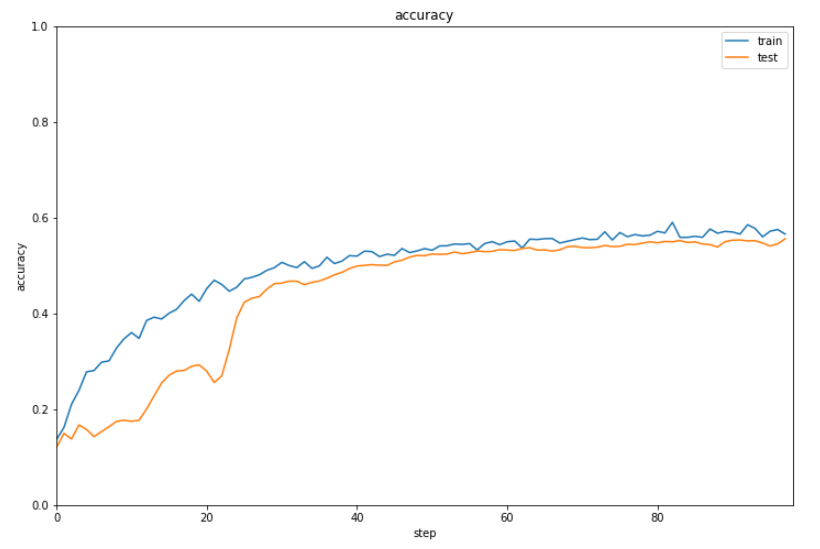
正解率は6割に届かない程度となりました。
ここから正解率を上げるために4層のニューラルネットワークにしていきます。
畳み込みニューラルネットワークのクラスを定義します。
1 | # 畳み込みニューラルネットワークのクラス作成 |
多段階の畳み込みニューラルネットワークと関数を定義します。
1 | # 多段階の畳み込みニューラルネットワーク |
GPUの設定を行います。
1 | # GPUの設定 |
結果を一旦初期化します。
1 | train_loss = [] |
最適化手法にAdamを設定します。
1 | # 最適化手法の設定 |
関数を定義します。
1 | def shift_labeled(labeled_data): |
確率勾配法で最適化し、結果をグラフ化します。
1 | from tqdm import tqdm |
2、3時間実行しているのですが、進捗が48%でまだ時間がかかるので一旦ここまでの結果を確認しておきます。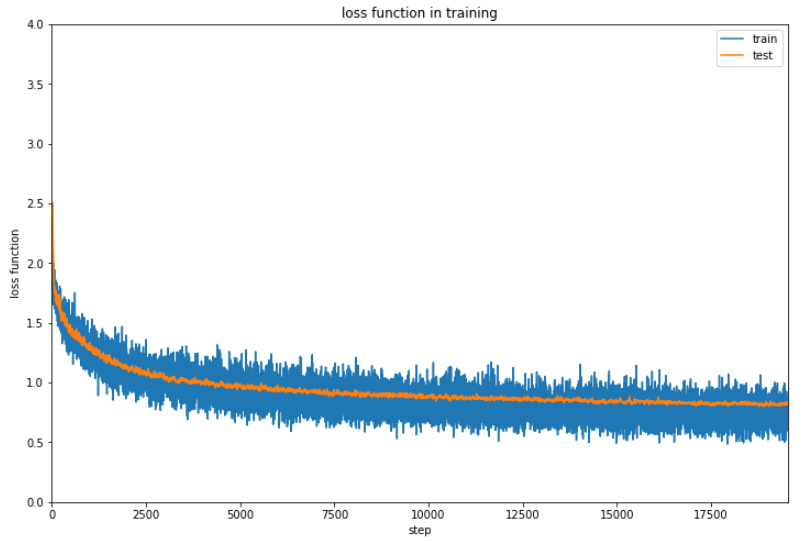
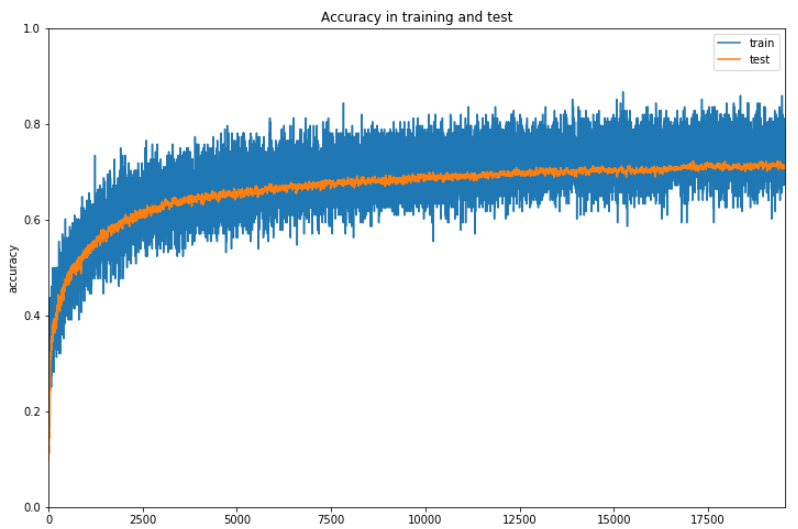
なんとか6割の正解率を超えてきているでしょうか。ただここまで時間がかかるのと正解率が微妙にしか上昇していないのでなんらかの改善の余地はあると思います。
5時間20分かかってようやく終了しました。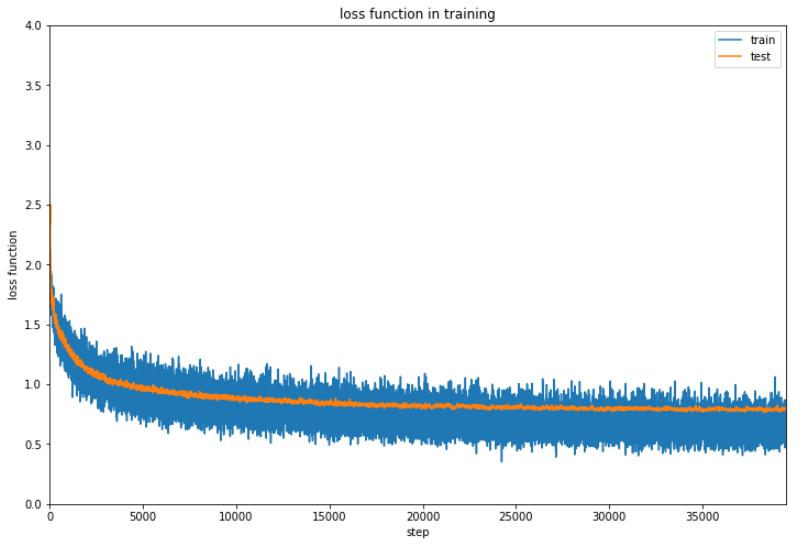
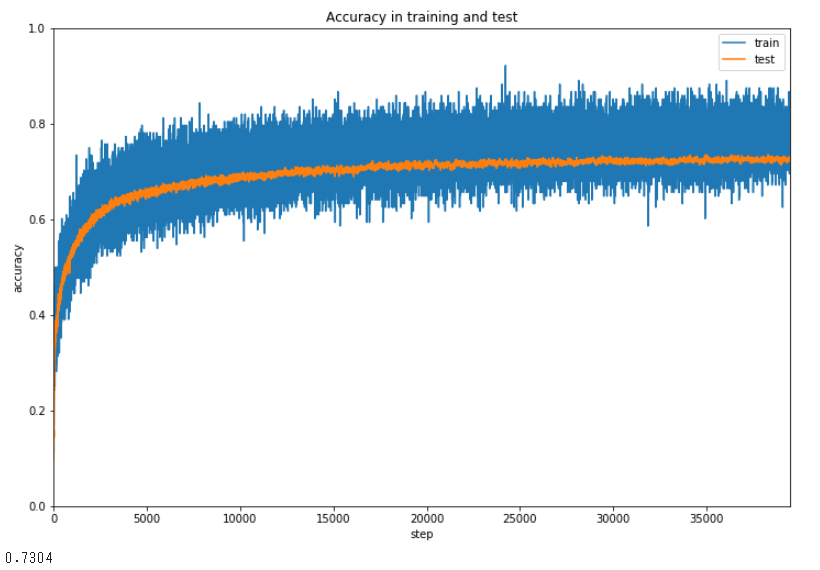
最終的な正解率は73%ですか。。。まー実用性があるといってもいいような気がします。
(Google Colaboratoryで動作確認しています。)