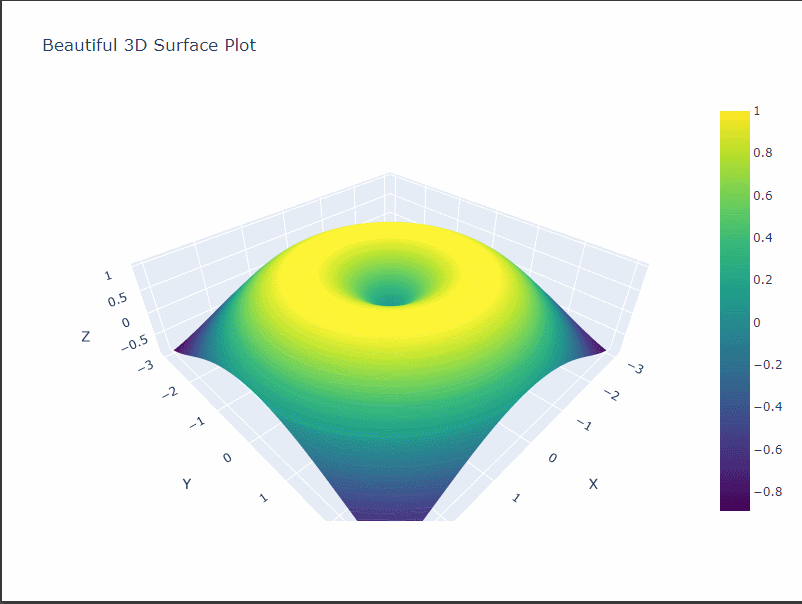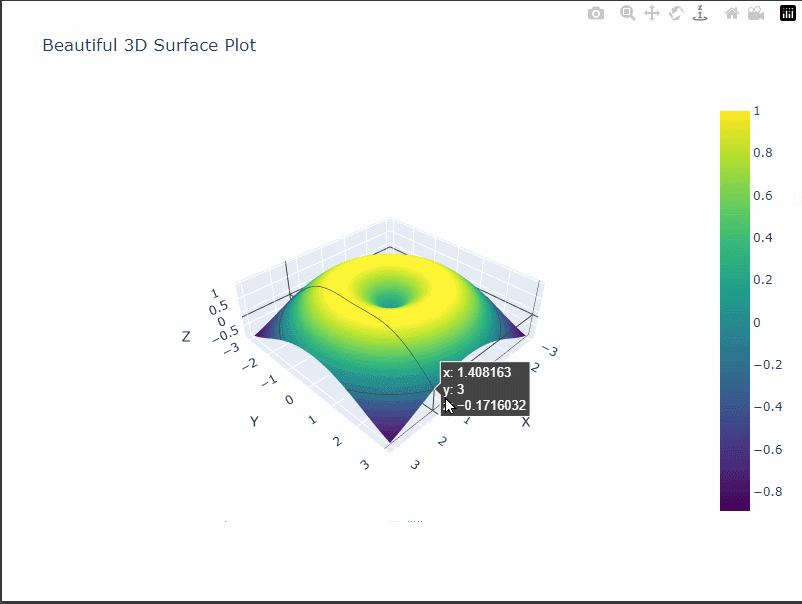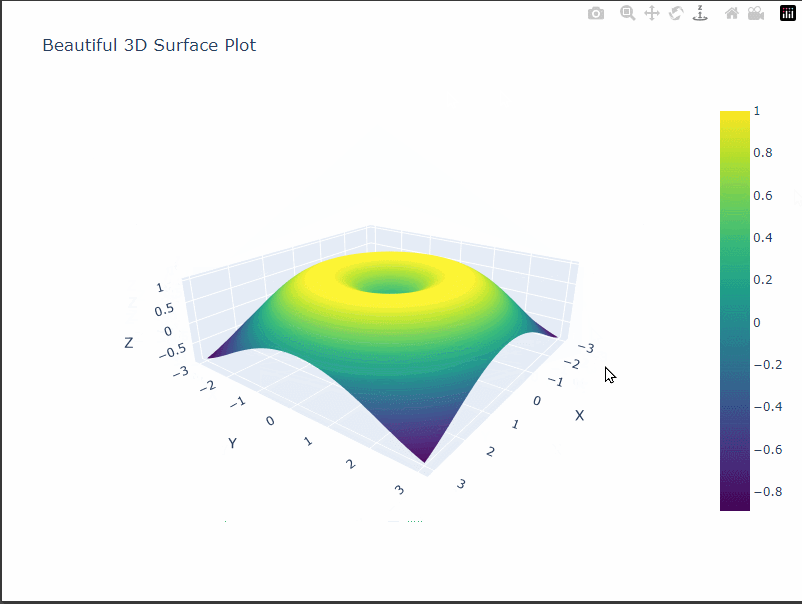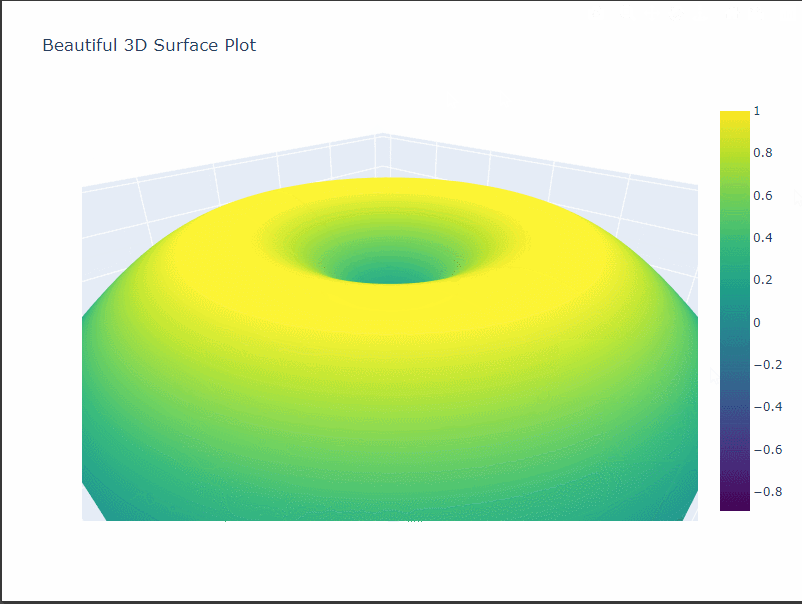
カタロイド曲面
カタロイド曲面は、2つの円錐の底面を共有する形状の曲面です。
その特徴は以下のとおりです。
1. 形状
- カタロイド曲面は、2つの円錐の底面を共有する面で構成されています。
- 中心部分には穴が開いた形状になっています。
- 曲面は中心から離れるにつれて高さが低くなっていきます。
2. 方程式
- カタロイド曲面の方程式は、$x^2 + y^2 - (x^2 + y^2)^2 = 0$ で表されます。
- この方程式は、平面上の点$(x, y)$の座標と、その点におけるz座標の値の関係を示しています。
3. 性質
- カタロイド曲面は、鎖線の形状をしており、そのため鎖線曲面とも呼ばれます。
- この曲面は、最小曲面の一種であり、曲面の面積が最小になる性質を持っています。
- カタロイド曲面は、石けんの膜の形状として知られており、物理学や工学の分野で重要な役割を果たしています。
4. 応用
- カタロイド曲面の形状は、建築物の設計や構造物の強度計算などに応用されています。
- また、流体力学の分野では、液体の表面張力によって生じる形状としてカタロイド曲面が研究されています。
カタロイド曲面は、特異な形状と数学的な性質を併せ持つ曲面であり、様々な分野で興味深い応用があります。
この曲面の理解は、曲面の幾何学的な性質を学ぶ上で重要です。
ソースコード
カタロイド曲面の方程式は以下のように表されます。
$$
x^2 + y^2 - (x^2 + y^2)^2 = 0
$$
この方程式をPythonで解いて、グラフ化するコードは次のようになります。
1 | import numpy as np |
このコードでは、最初にカタロイド曲面の方程式を関数catenoid(x, y)として定義しています。
次に、グラフ化する範囲をnp.linspace関数で設定し、np.meshgrid関数を使ってグリッド点を生成しています。
catenoid(X, Y)で方程式の値を計算し、ax.plot_surface関数で3D曲面を描画しています。rstrideとcstrideで表示解像度を調整できます。cmapでカラーマップを指定しています。
最後に、グラフにタイトルとラベルを付けて、plt.show()でグラフを表示しています。
実行すると、カタロイド曲面の3D グラフが表示されます。
[実行結果]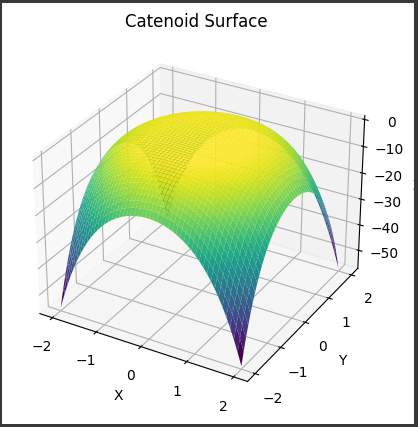
ソースコード解説
コードの構成は以下の通りです。
1. ライブラリのインポート
1 | import numpy as np |
NumPyとMatplotlibライブラリをインポートしています。NumPyは数値計算、Matplotlibは図の描画に使用されます。
さらに、Matplotlibの3D プロットを行うためにAxes3Dモジュールをインポートしています。
2. 方程式の定義
1 | def catenoid(x, y): |
カタロイド曲面の方程式 $x^2 + y^2 - (x^2 + y^2)^2 = 0$ を関数 catenoid(x, y) として定義しています。
この関数は、入力された x と y の値に対応する z の値を返します。
3. グラフ化する範囲の設定
1 | x = np.linspace(-2, 2, 50) |
np.linspace(-2, 2, 50) で、$-2$から$2$までの$50$個の点を等間隔で生成しています。
これにより、グラフ化する x と y の範囲が設定されます。
次に、np.meshgrid(x, y) で X と Y の座標グリッドを作成しています。
最後に、catenoid(X, Y) で X と Y に対応する Z の値を計算しています。
4. 3D グラフの描画
1 | fig = plt.figure() |
最初に plt.figure() で新しい図のウィンドウを作成し、fig.add_subplot(111, projection='3d') で3D プロットの領域を確保しています。
次に、ax.plot_surface(X, Y, Z, rstride=1, cstride=1, cmap='viridis') でカタロイド曲面を描画しています。
rstrideとcstrideで描画解像度を、cmapでカラーマップを設定しています。
最後に、ax.set_title()、ax.set_xlabel()、ax.set_ylabel()、ax.set_zlabel() でグラフのタイトルと軸ラベルを設定し、plt.show() でグラフを表示しています。
このスクリプトを実行すると、カタロイド曲面の3D グラフがウィンドウに表示されます。
グラフには曲面の特徴的な形状と高さに応じた色分けがなされています。
グラフ解説
[実行結果]
グラフには以下の特徴があります。
- カタロイド曲面は、2つの円すい面が共有する部分から成る曲面です。
- 曲面の中心部分には穴が開いた形状になっています。
- 曲面の高さは中心から離れるほど低くなっていきます。
- 曲面の色は高さに応じて変化しており、濃い色が高い部分、薄い色が低い部分を表しています。
このようにカタロイド曲面のグラフは、特徴的な形状と色分けされた高さの変化を視覚的に捉えることができます。