FXのトレードを学習させて、利益総額が増えるかどうかを確認します。
インストール
Windowsで実行する場合、Microsoft MPIをインストールする必要があります。
Microsoft MPI - https://www.microsoft.com/en-us/download/details.aspx?id=100593
さらに下記のコマンドを実行し学習のための環境を準備します。
1
2
3
4
| pip install stable-baselines[mpi]
pip install tensorflow==1.14.0
pip install pyqt5
pip install imageio
|
学習投資
FXトレードを学習してから投資を行う処理を実装します。
[コード]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
| import gym
import gym_anytrading
import matplotlib.pyplot as plt
import os
from gym_anytrading.envs import TradingEnv, ForexEnv, StocksEnv, Actions, Positions
from gym_anytrading.datasets import FOREX_EURUSD_1H_ASK, STOCKS_GOOGL
from stable_baselines.common import set_global_seeds
from stable_baselines.common.vec_env import DummyVecEnv
from stable_baselines import PPO2
from stable_baselines.bench import Monitor
# ログフォルダの作成
log_dir = './logs/'
os.makedirs(log_dir, exist_ok=True)
# 環境を生成(frame_boundはデータセット内の訓練範囲を開始行数と終了行数で指定)
env = gym.make('forex-v0', frame_bound=(50, 100), window_size=10)
env = Monitor(env, log_dir, allow_early_resets=True)
# シードの指定
env.seed(0)
set_global_seeds(0)
# ベクトル化環境の生成
env = DummyVecEnv([lambda: env])
# モデルの生成
model = PPO2('MlpPolicy', env, verbose=1)
# モデルの読み込み(学習済みデータがある場合)
# model = PPO2.load('trading_model')
# モデルの学習
model.learn(total_timesteps=128000)
# モデルの保存
model.save('trading_model')
# モデルのテスト
env = gym.make('forex-v0', frame_bound=(50, 100), window_size=10)
env.seed(0)
state = env.reset()
while True:
# 行動の取得
action, _ = model.predict(state)
# 1ステップ実行
state, reward, done, info = env.step(action)
# エピソード完了
if done:
print('info:', info)
break
# グラフのプロット
plt.cla()
env.render_all()
plt.show()
|
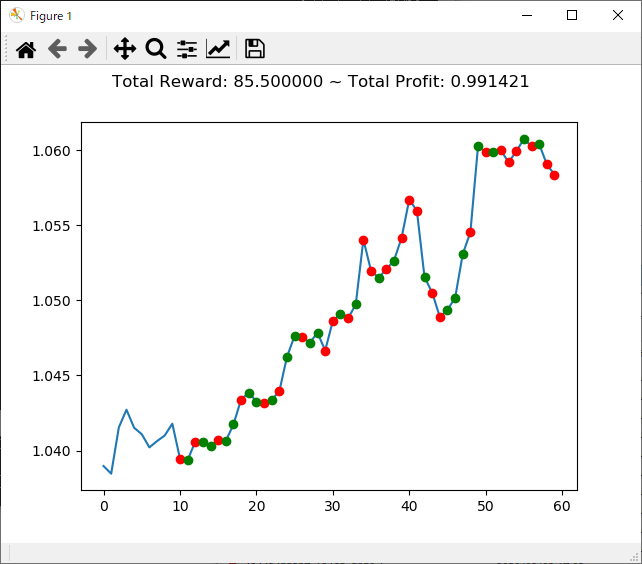
実行結果は下記のとおりです。
[実行結果]
info: {'total_reward': 76.70000000000952, 'total_profit': 0.993213633946179, 'position': 1}
累計報酬(total_reward)、純利益(total_profit)、ポジション(position:0がショート、1がロング)が表示されます。
ランダムの時と比べてあまり結果がよくなりませんでした・・・というよりむしろ成績が落ちていて、もう少し理解を深める必要がありそうです。
グラフに表示される結果は以下の通りです。
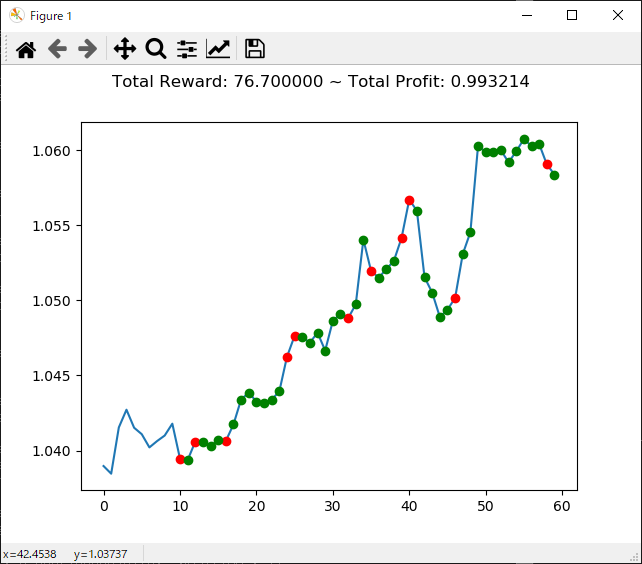
赤●が「0:Sell」で落ちる予想、緑●が「1:Buy」で上がる予想を表します。