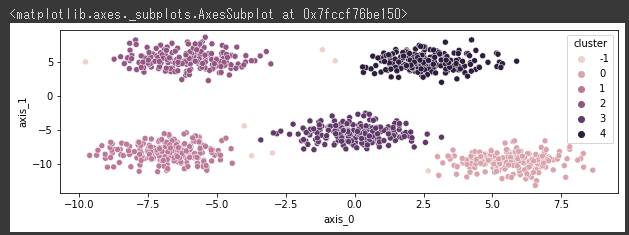
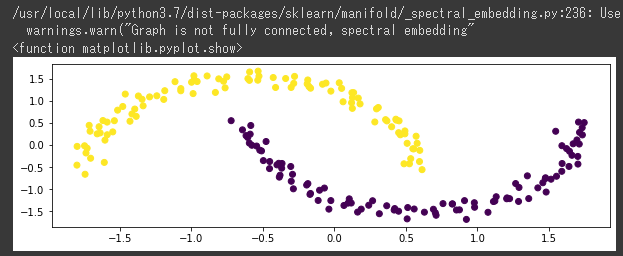
DBSCAN(Density-Based Spatial Clustering of Applications with Noise)を使って、クラスタリングを行います。
DBSCANは、密度準拠クラスタリングのアルゴリズムを使います。
密接している点を同じグループにまとめ、低密度領域にある点をノイズ(外れ値)と判定します。
各点は自身の半径以内に点がいくつあるかでその領域をクラスタとして判断するため、クラスタ数をあらかじめ決めなくていいという長所があります。
近傍の密度がある閾値を超えている限り、クラスタを成長させ続け、半径以内にない点はノイズになります。
データセットの準備
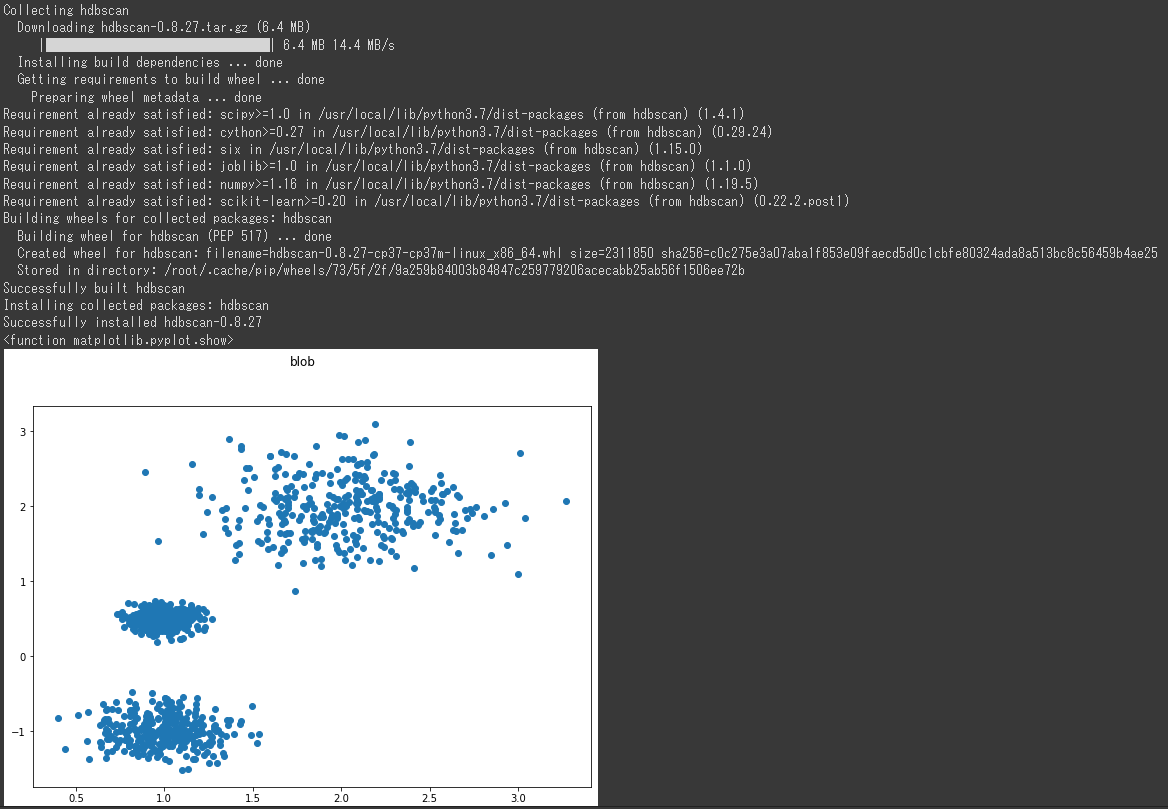
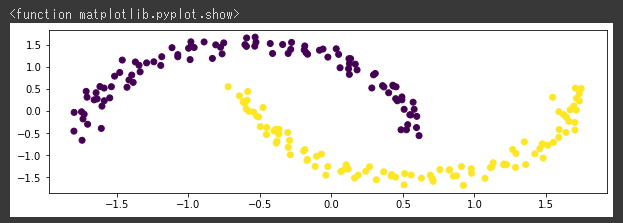
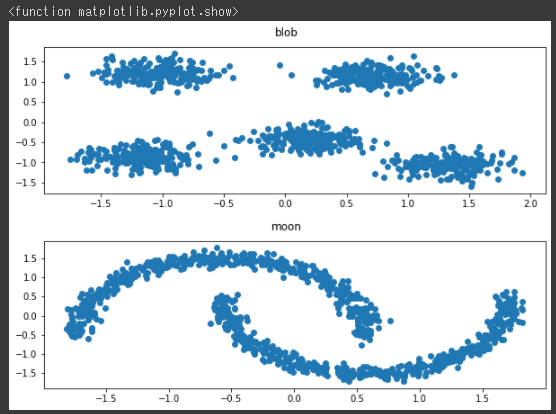
今回は2種類のデータセットを生成します。
1つ目のデータセットとして塊データを生成し、可視化します。(1~9行目)
2つ目のデータセットとしてムーンデータを生成し、可視化します。(11~19行目)
[Google Colaboratory]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| X = datasets.make_blobs(n_samples=1000, random_state=10, centers=5, cluster_std=1.2)[0]
sc = preprocessing.StandardScaler()
X_norm = sc.fit_transform(X)
x = X_norm[:,0]
y = X_norm[:,1]
plt.figure(figsize=(10,3))
plt.scatter(x,y)
plt.suptitle("blob")
plt.show
X_moon = datasets.make_moons(n_samples=1000, noise=0.05, random_state=0)[0]
sc = preprocessing.StandardScaler()
X_moon_norm = sc.fit_transform(X_moon)
x_moon = X_moon_norm[:,0]
y_moon = X_moon_norm[:,1]
plt.figure(figsize=(10,3))
plt.scatter(x_moon,y_moon)
plt.suptitle("moon")
plt.show
|
[実行結果]
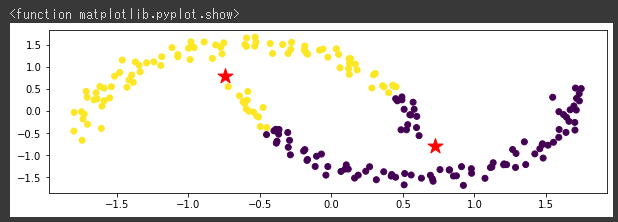
ムーンデータをクラスタリング
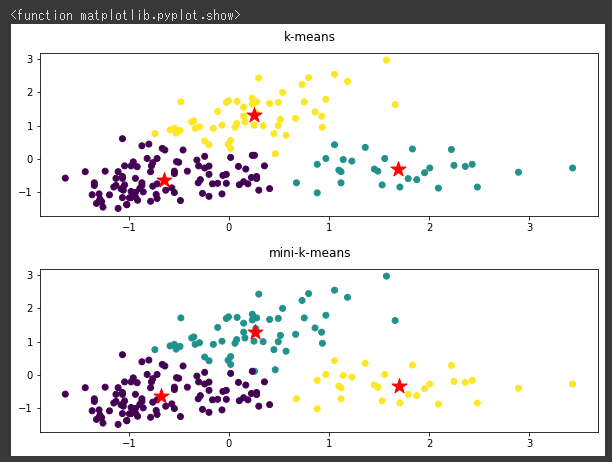
まずk-meansのクラスタリング結果を可視化し(1~7行目)、その後にDBSCANでクラスタリングを行ってから同じく可視化しています(9~14行目)。
DBSCANモデルはcluster.DBSCAN関数で作成しします。(9行目)
[Google Colaboratory]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
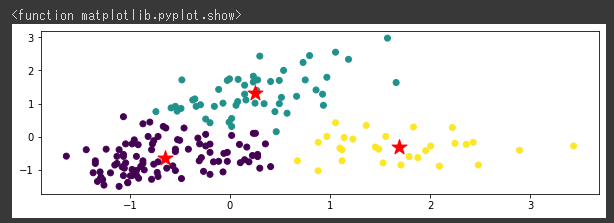
| km_moon = cluster.KMeans(n_clusters=2)
z_km_moon = km_moon.fit(X_moon_norm)
plt.figure(figsize = (10,3))
plt.scatter(x_moon,y_moon, c=z_km_moon.labels_)
plt.scatter(z_km_moon.cluster_centers_[:,0],z_km_moon.cluster_centers_[:,1],s=250, marker="*",c="red")
plt.suptitle("k-means")
plt.show
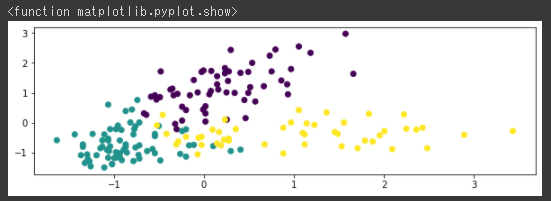
dbscan = cluster.DBSCAN(eps=0.2, min_samples=5, metric="euclidean")
labels = dbscan.fit_predict(X_moon_norm)
plt.figure(figsize=(10,3))
plt.scatter(x_moon,y_moon, c=labels)
plt.suptitle("dbscan")
plt.show
|
[実行結果]
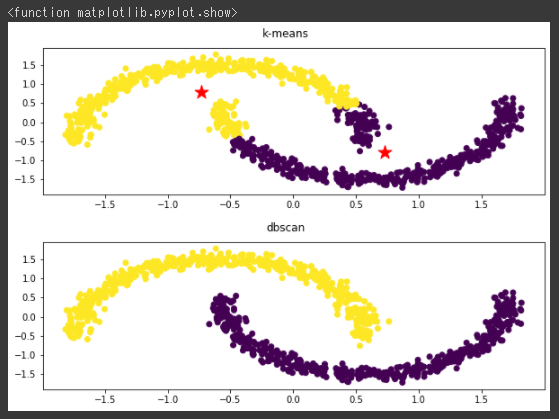
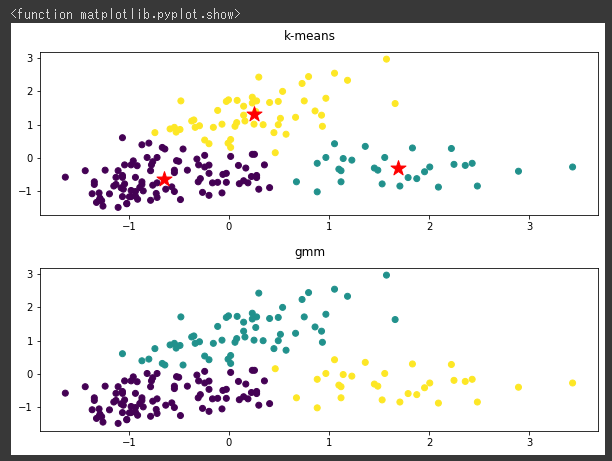
k-meansではうまく分類できていませんが、DBSCANだときちんと分類されています。
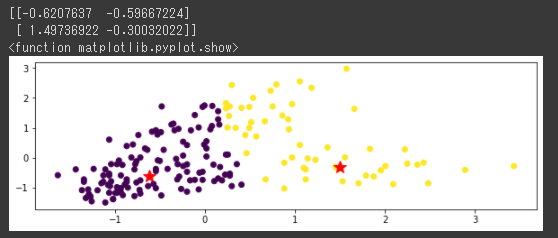
塊データをクラスタリング
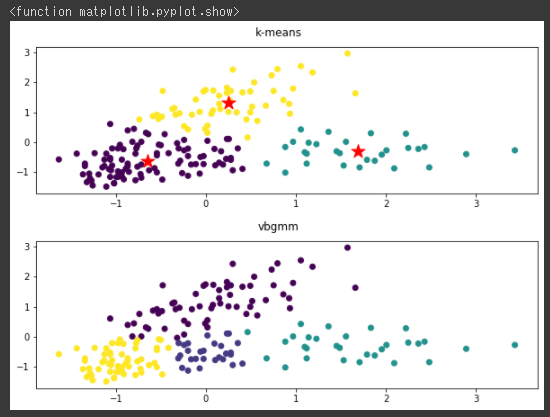
塊データもk-meansとDBSCANでクラスタリングを行ってみます。
[Google Colaboratory]
1
2
3
4
5
6
7
8
9
10
11
12
13
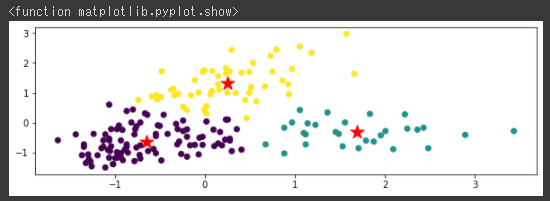
| km=cluster.KMeans(n_clusters=5)
z_km=km.fit(X_norm)
plt.figure(figsize=(10,3))
plt.scatter(x,y, c=z_km.labels_)
plt.scatter(z_km.cluster_centers_[:,0],z_km.cluster_centers_[:,1],s=250, marker="*",c="red")
plt.suptitle("k-means")
dbscan = cluster.DBSCAN(eps=0.2, min_samples=5, metric="euclidean")
labels = dbscan.fit_predict(X_norm)
plt.figure(figsize=(10,3))
plt.scatter(x,y, c=labels)
plt.suptitle("dbscan")
plt.show
|
[実行結果]
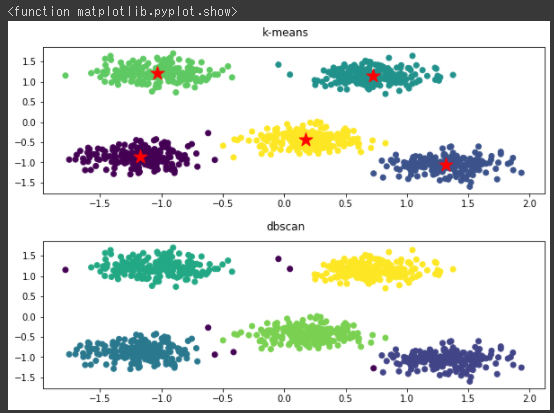
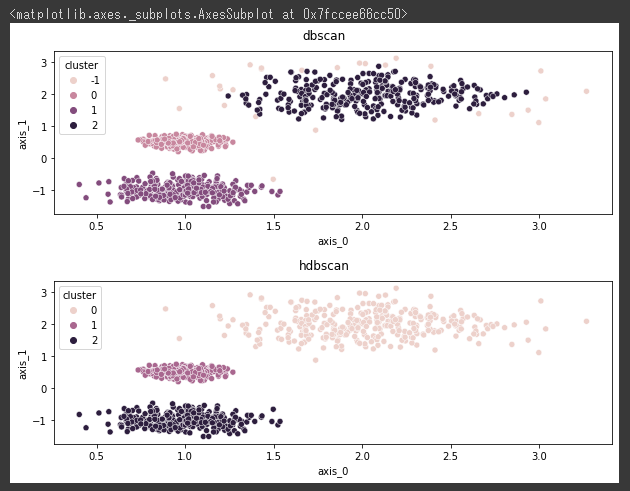
今回は両方のアルゴリズムでうまく分類できているようです。
DBSCANは、データの密度を基準とするアルゴリズムで、全データ点はコア点、到達可能点、ノイズ点に分類されます。
8行目のepsパラメータで決められた半径内にmin_samplesパラメータの値以上の点が集まっていれば、それをコア点であると判断します。
コア点ではないデータでも、近くにあるコア点からeps半径の中に入っているものは到達可能点であると判断します。
そのどちらにもなれなかった点はノイズ点(外れ値)として分類されます。
DBSCANにおいて、epsとmin_samplesはとても重要なパラメータだということになります。
DBSCANの総括
DBSCANは球の形状を前提とせず、ノイズ分類もできて、クラスタ数の指定も必要ないクラスタリングになります。
デメリットとしては、全データ点を対象とした反復計算を実施しているため計算コストが高く、リアルタイム性が求められるよな場合には不向きです。
またデータが密集しているとパラメータ調整が難しくなるという一面もあります。