for info in info_lst: tp = info['type'] x, y = info['x'] - 1, info['y'] - 1# [1 ~ n ]の範囲を、[0 ~ n - 1 ]の範囲にする
# 動物の番号の範囲をチェック if x < 0or x >= n or y < 0or y >= n: print('動物番号の範囲チェックエラー', info) ans += 1 else: if tp == 1: # 同じ種類の場合 if uf.same(x, y + n) or uf.same(x, y + n * 2): print('矛盾', info) ans += 1 else: print('同じ種類としてグループ化', info) uf.union(x, y) uf.union(x + n, y + n) uf.union(x + n * 2, y + n * 2) else: # xはyを食べる場合 if uf.same(x, y) or uf.same(x, y + n * 2): print('矛盾', info) ans += 1 else: print('食べられる種類としてグループ化', info) uf.union(x, y + n) uf.union(x + n, y + n * 2) uf.union(x + n * 2, y)
# print(uf.all_group_members()) # for group in uf.all_group_members(): # members = uf.members(group) # if len(members) > 1: # print(members) print() print('答え', ans)
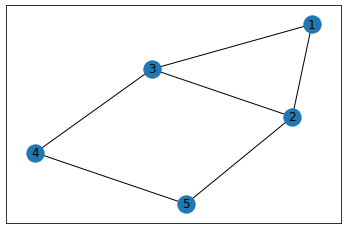
人 1 から 人 N までのN 人の人がいます。
「人Ai と人 Bi は友達である」という情報が M 個与えられます。
同じ情報が複数回与えられることもあります。
X と Y が友達、かつ、Y と Z が友達ならば、X と Z も友達です。
また、M 個の情報から導くことができない友達関係は存在しません。
いじわるな高橋君は、このN人をいくつかのグループに分け、全ての人について「同じグループの中に友達がいない」という状況を作ろうとしています。
最小でいくつのグループに分ければ良いでしょうか?
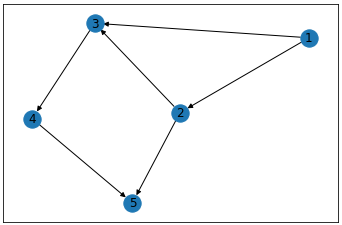
for l in lst: # 友達関係から友達グループを作成する uf.union(l[0]-1, l[1]-1)
ans = 0# 友達がいない状況をつくるためのグループ数 for g in uf.all_group_members().values(): # 友達グループごとにループ print(f'友達グループ', g) # 友達グループのメンバー g_size = len(g) # 友達の数 # 友達の数が「友達がいない状況をつくるためのグループ数」より大きかったら if g_size > ans: ans = g_size # グループ数に友達数を設定
# n個の要素を0 ~ n - 1のインデックスで管理する classUnionFind(): def__init__(self, n): self.n = n # 要素の数 self.parents = [-1] * n # 各要素の親要素の番号を格納するリスト
deffind(self, x): # 要素[x]が属するグループの親を返す if self.parents[x] < 0: return x else: self.parents[x] = self.find(self.parents[x]) return self.parents[x]
defunion(self, x, y): # 要素[x]が属するグループと要素yが属するグループとを併合 x = self.find(x) y = self.find(y) if x == y: return if self.parents[x] > self.parents[y]: x, y = y, x self.parents[x] += self.parents[y] self.parents[y] = x
ある工場では製品 p と製品 q を製造しています。
製品 p と製品 q を製造するには原料 m と原料 n が必要で、次のような条件となっています。
・製品 p を1kg製造するには原料 m が1kg、原料 n が2kg必要。
・製品 q を1kg製造するには原料 m が3kg、原料 n が1kg必要。
・原料 m の在庫は30kg、原料 n の在庫は40kgあります。
・単位量当たりの利益は、製品 p が1万円、製品 q が2万円です。
この条件で利益を最大にするためには、製品 p と製品 q をそれぞれ何kg製造すればよいでしょうか。
製品 p の製造量を x kg、と製品 q の製造量を y kgとすると以下のように不等号をつかった式にまとめることができます。
#--------入力例1---------------- n = 6 a = [-45,-41,-36,-36,26,-32] b = [-16,30,77,-46,62,45] c = [42,56,-37,-75,-10,-6] d = [22,-27,53,30,-38,-54] #-------------------------------- # リストCとリストDからの取り出し方の組を全部列挙 cd = [c1 + d1 for c1 in c for d1 in d]
cnt = 0 for a1 in a: # リストAを全部列挙 for b1 in b: # リストBを全部列挙 # リストCとリストDからの和がabとなるように取り出す ab = (a1 + b1)*-1 if ab in cd: cnt += 1 print(cnt)