Genotype-Guided Treatment Selection with Python
Precision medicine promises to replace the “one dose fits all” paradigm with treatment decisions tailored to each patient’s genome. In practice, this means combining pharmacogenomic data — variants in drug-metabolizing enzymes, transporters, and drug targets — with dose-response models to select both the right drug and the right dose for a given patient. This is fundamentally a constrained optimization problem: maximize expected clinical benefit while keeping toxicity risk below an acceptable threshold.
In this post, we build a concrete example: a patient with a known genetic profile is being considered for one of five candidate treatments. We optimize the dose for each candidate under a toxicity ceiling, then rank the treatments to recommend the one offering the best genotype-adjusted outcome.
1. From Genotype to a Composite Pharmacogenomic Score
A patient’s genetic profile is represented by allele dosages $x_i \in {0,1,2}$ at $n$ relevant SNPs (e.g., variants in CYP2D6, CYP2C19, DPYD), each with an effect weight $w_i$ describing its influence on drug clearance. We collapse this into a single interpretable metabolizer score:
$$
g = \sigma!\left(\frac{\sum_{i=1}^{n} w_i x_i - \mu}{s}\right), \qquad \sigma(z) = \frac{1}{1+e^{-z}}
$$
where $g \in (0,1)$ ranges from poor metabolizer ($g \to 0$) to ultra-rapid metabolizer ($g \to 1$), and $\mu, s$ are calibration constants centering the score on a typical population range.
2. Genetics-Modulated Dose-Response Models
For each candidate drug $k$, efficacy and toxicity follow Hill/Emax pharmacodynamic models, but their potency parameters shift with the patient’s metabolizer score:
$$
E_k(d,g) = E_{max,k}\cdot\frac{d^{,n_k}}{EC50_k(g)^{,n_k}+d^{,n_k}}, \qquad
T_k(d,g) = T_{max,k}\cdot\frac{d^{,m_k}}{TC50_k(g)^{,m_k}+d^{,m_k}}
$$
$$
EC50_k(g) = EC50_k^0\big(1+\alpha_k(g-0.5)\big), \qquad
TC50_k(g) = TC50_k^0\big(1+\beta_k(g-0.5)\big)
$$
The coefficients $\alpha_k, \beta_k$ encode how a patient’s metabolic speed shifts the effective potency and safety margin of drug $k$ — a fast metabolizer might need a higher dose to reach the same efficacy ($\alpha_k>0$), or might clear the drug fast enough to tolerate higher doses before toxicity appears ($\beta_k>0$).
3. The Optimization Problem
For a fixed patient genotype $g^*$, we choose the dose $d$ that maximizes a clinical utility function penalizing toxicity, subject to a hard toxicity ceiling:
$$
\max_{d \in [d_{min,k},,d_{max,k}]} ; B_k(d) = E_k(d,g^*) - \lambda, T_k(d,g^*)
\quad \text{s.t.} \quad T_k(d,g^*) \le T_{allow}
$$
We solve this independently for all five candidate drugs and select the one with the highest feasible net benefit — this is the genotype-guided recommendation.
4. Full Implementation
1 | # ============================================================ |
Output
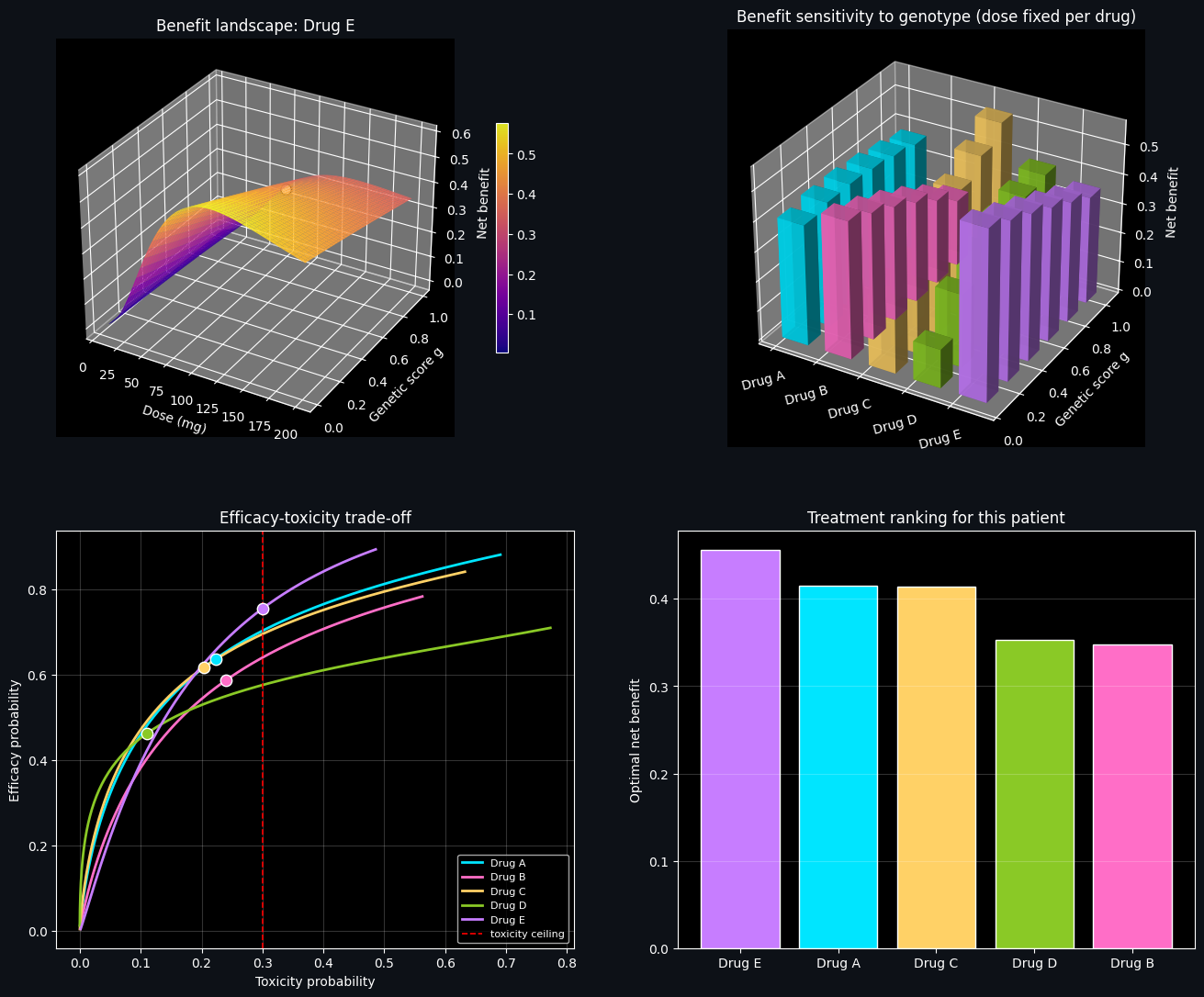
Patient pharmacogenomic score g = 0.562 Drug A: dose= 59.67 efficacy=0.638 toxicity=0.223 benefit=0.415 [OK] Drug B: dose= 39.63 efficacy=0.588 toxicity=0.240 benefit=0.348 [OK] Drug C: dose= 76.43 efficacy=0.618 toxicity=0.204 benefit=0.414 [OK] Drug D: dose= 18.68 efficacy=0.463 toxicity=0.110 benefit=0.353 [OK] Drug E: dose=120.93 efficacy=0.756 toxicity=0.300 benefit=0.456 [OK] --> Recommended treatment: Drug E
5. Code Walkthrough
Genetic score construction. The snp_genotype array encodes the patient’s allele dosage at six pharmacogenomic markers, and snp_weight encodes each variant’s directional effect on metabolic activity. The dot product is passed through a logistic sigmoid, producing a bounded score $g \in (0,1)$ that is easy to interpret and easy to plug into downstream pharmacodynamic equations — this mirrors how polygenic risk scores are constructed in practice.
Dose-response functions. efficacy() and toxicity() implement the Hill-equation model described above. Both are fully vectorized with NumPy, so they accept scalars, 1D arrays, or 2D meshgrids without any code changes — this is what lets the same functions serve the optimizer and the 3D surface plot.
Constrained optimization. For each drug, we use scipy.optimize.differential_evolution, a global, gradient-free optimizer well suited to the potentially non-convex trade-off between efficacy and toxicity. The toxicity ceiling is enforced with a NonlinearConstraint object (rather than the older dict-based constraint API, which is deprecated and less numerically robust). Since the search space is one-dimensional (the dose), convergence is essentially instantaneous — no further speed-up is required here.
Selection logic. After optimizing all five drugs independently, we filter to only the feasible ones (those respecting the toxicity ceiling) and pick the drug with the highest net benefit. If no drug is feasible, we fall back to the best available option and flag it — this avoids ever silently recommending a treatment that violates safety constraints.
6. Reading the Graphs
Top-left (3D surface). This shows how net clinical benefit for the recommended drug varies jointly with dose and genetic score. The white marker sits at the patient’s actual genotype and optimal dose — the peak (or near-peak) of the ridge. The shape of this surface makes it visually clear why a fixed, non-personalized dose would be suboptimal for patients at the opposite end of the metabolizer spectrum.
Top-right (3D bar comparison). Here we take each drug’s dose (optimized specifically for our patient) and ask: how would that same dose perform across a range of hypothetical genetic scores? Drugs with flatter bar profiles are more “robust” to genotype misestimation, while drugs with steep gradients are highly genotype-sensitive — valuable information when confidence in a genetic test is imperfect.
Bottom-left (efficacy-toxicity trade-off). Each curve traces out the achievable combinations of efficacy and toxicity as dose is swept across its allowed range for a given drug, evaluated at the patient’s actual genotype. The red dashed line marks the toxicity ceiling; curves that stay well left of it before saturating in efficacy are the most attractive candidates. The dots mark each drug’s optimizer-selected operating point.
Bottom-right (ranking bar chart). A direct summary: the optimal net benefit achieved by each drug, sorted from best to worst. Gray bars (if any) indicate drugs that could not satisfy the toxicity constraint at any dose and were excluded from consideration.
7. Closing Notes
This example is a simplified, illustrative model — the pharmacodynamic parameters are synthetic rather than derived from real trial data, and any real clinical decision support system would need far more rigorous, validated dose-response models, uncertainty quantification, and regulatory oversight. But the underlying optimization structure — genotype-conditioned dose-response curves, a constrained multi-objective utility function, and a global optimizer sweeping across candidate treatments — reflects the computational backbone of real pharmacogenomics-driven decision tools, and generalizes naturally to more markers, more drugs, or multi-dose regimens.