
放射線源の観測データのクラスタリング
宇宙に関する問題を解決するために、scikit-learnを使用してクラスタリングを行います。
具体的なデータセットとして、宇宙からの放射線源の観測データを考えます。
このデータセットを用いて、放射線源のクラスタを特定し、その結果をグラフ化します。
まず、適切なデータセットを用意しましょう。
宇宙からの放射線源のデータセットは、実際のものではなく、架空のデータセットとして扱います。
以下のサンプルコードでは、make_blobs関数を使用して3つのクラスタを持つデータセットを生成します。
1 | import numpy as np |
このサンプルコードでは、make_blobs関数を使用して3つのクラスタを持つデータセットを生成し、KMeansクラスタリングアルゴリズムを適用しています。
結果をプロットすると、各クラスタの中心が赤い”X”で表示され、データ点が色分けされたクラスタに属していることがわかります。
[実行結果]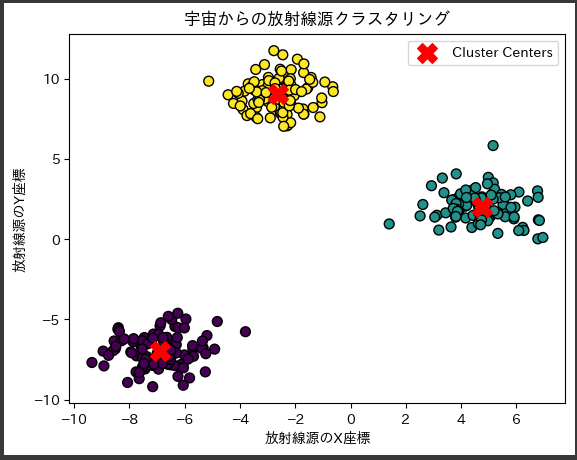
この例は架空のデータを使用していますが、実際の宇宙データセットを用いることで、クラスタリングアルゴリズムを実際の天文データに適用し、異なる放射線源のグループを発見することができます。
ソースコード解説
このソースコードは、仮想の宇宙からの放射線源データセットを生成し、それにKMeansクラスタリングアルゴリズムを適用して結果を可視化するためのものです。
以下にソースコードの章立てと詳細な説明を示します。
1. ライブラリのインポート
1 | import numpy as np |
numpy:数値計算を行うためのライブラリmatplotlib.pyplot:グラフの描画や可視化のためのライブラリmake_blobs:クラスタリングのための仮想のデータセットを生成するための関数KMeans:KMeansクラスタリングアルゴリズムを提供するscikit-learnのクラス
2. 仮想の宇宙からの放射線源データセット生成
1 | X, y = make_blobs(n_samples=300, centers=3, random_state=42, cluster_std=1.0) |
make_blobs関数を使用して、3つのクラスタを持つ仮想の宇宙からの放射線源データセットを生成n_samples:データセットのサンプル数centers:生成するクラスタの数random_state:再現性のための乱数シードcluster_std:クラスタの標準偏差
3. KMeansクラスタリングを実行
1 | kmeans = KMeans(n_clusters=3) |
KMeansクラスを用いてクラスタリングモデルを初期化し、fitメソッドでデータに適用n_clusters:クラスタの数
4. クラスタリング結果を取得
1 | labels = kmeans.labels_ |
labels:各データポイントが属するクラスタのラベルcenters:各クラスタの中心座標
5. データとクラスターセンターをプロット
1 | plt.scatter(X[:, 0], X[:, 1], c=labels, cmap='viridis', edgecolor='k', s=50) |
plt.scatterを使用してデータポイントを散布図としてプロットc=labelsによりクラスタごとに色分けし、cmap='viridis'でカラーマップを指定plt.scatterでクラスターセンターを赤い”X”でプロット- グラフのタイトル、軸ラベル、凡例を設定
plt.show()でグラフを表示
このソースコードは、データの生成からKMeansクラスタリングの実行、結果の可視化までを一貫して実施しています。
最終的なグラフでは、異なるクラスタのデータポイントと各クラスタの中心が視覚的に表示され、クラスタリングの効果が確認できます。
結果解説
[実行結果]
上記のグラフは、宇宙からの放射線源のクラスタリング結果を可視化したものです。
以下に各要素の説明を記載します。
1. データポイント:
- 散布図上に散らばる点は、仮想の宇宙からの放射線源を表しています。
各点はデータセット内の1つの観測データを表し、その座標は宇宙の座標を模しています。
2. クラスタ:
- 色分けされた領域は、KMeansクラスタリングアルゴリズムによって同じクラスタに分類されたデータポイントを示しています。
この例では3つのクラスタがあり、それぞれ異なる色で表されています。
各クラスタは同じ色で示され、その色はcmap='viridis'によって指定されています。
3. クラスターセンター:
- 赤い”X”は各クラスタの中心を示しています。
これらの点は、KMeansアルゴリズムによって見つかったクラスタの中心座標です。
4. グラフタイトルと軸ラベル:
- グラフのタイトルは宇宙からの放射線源クラスタリングとなっており、軸ラベルはそれぞれ放射線源のX座標と放射線源のY座標です。
このグラフを見ると、KMeansクラスタリングがデータセットを3つの異なるクラスタに効果的に分類していることがわかります。
各クラスタの中心(赤い”X”)は、そのクラスタのデータポイントが集まる中心点を表しています。
このような可視化を通じて、異なる放射線源のグループがどのように分布しているかを把握することができます。