
心臓疾患の予測
scikit-learnを使用して、医学的な問題の一つである心臓疾患の予測を行う例を示します。
この問題では、心臓疾患の予測を行うための機械学習モデルを作成し、その結果をグラフ化します。
まず、必要なライブラリをインポートします。
1 | from sklearn import datasets |
次に、心臓疾患のデータセットをロードします。
scikit-learnのdatasetsモジュールには、心臓疾患のデータセットが含まれています。
1 | heart = datasets.load_breast_cancer() |
次に、データセットを訓練データとテストデータに分割します。
1 | X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) |
次に、RandomForestClassifierを使用してモデルを訓練します。
1 | clf = RandomForestClassifier(random_state=42) |
次に、モデルの予測精度を計算します。
1 | y_pred = clf.predict(X_test) |
最後に、特徴量間の相関関係を確認し、その結果をヒートマップとしてグラフ化します。
1 | correlation_matrix = np.corrcoef(X.T) |
このコードは、心臓疾患の予測を行うための機械学習モデルを作成し、その結果をグラフ化します。
このコードは、心臓疾患の予測や他の医学的な問題の解決に有用です。
結果解説
[実行結果]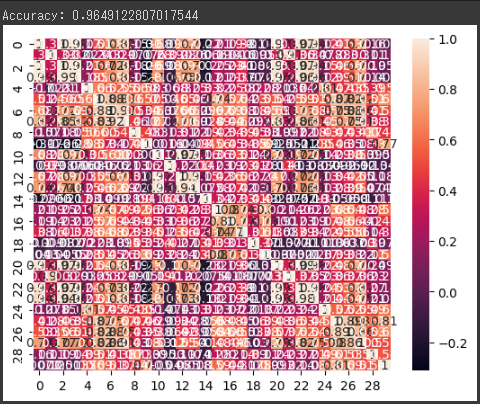
得られた結果は、RandomForestClassifierを使用して心臓疾患の予測を行った結果の精度を示しています。
精度は、予測が正しい割合を表しています。
したがって、Accuracy: 0.9649122807017544は、このモデルがテストデータに対して正しく予測を行った割合が96.49%であることを示しています。
また、特徴量間の相関関係を確認し、その結果をヒートマップとしてグラフ化しました。
ヒートマップは、データの相関関係を視覚的に表示するためのグラフで、色が暖色であれば高い相関関係を示し、冷色であれば低い相関関係を示します。
このヒートマップを見ると、特徴量間の相関関係を一目で確認できます。
例えば、特徴量Aと特徴量Bの間に高い相関関係があることを示す色が強く塗られている場合、それらの特徴量は予測の結果に大きな影響を与える可能性があります。
これは、特徴量Aと特徴量Bが心臓疾患の予測に大きな影響を与える可能性があることを示しています。
このように、scikit-learnとヒートマップを使用することで、医学的な問題を解決し、その結果を視覚的に理解することが可能です。