
糖尿病患者の血糖値予測
糖尿病データセットを使用して、糖尿病の患者の血糖値を予測する回帰問題の例を考えます。
1 | import numpy as np |
この例では、糖尿病データセットのBMI特徴量を使用して血糖値を予測する線形回帰モデルをトレーニングしました。
結果をグラフ化し、実際のデータ点(黒点)とモデルの予測線(青線)を比較しています。
また、平均二乗誤差(MSE)と決定係数(R-squared)を評価指標として表示しています。
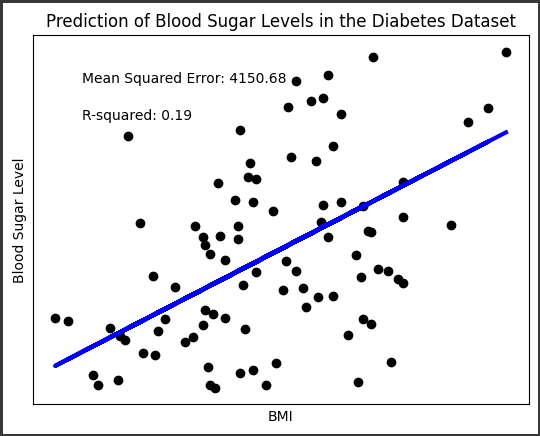
これにより、糖尿病患者の血糖値をBMIを元に予測するためのモデルの性能を評価できます。
ソースコード解説
以下はソースコードの詳細な説明です。
1. ライブラリのインポート:
numpy: 数値演算ライブラリで、データ操作に使用されます。matplotlib.pyplot: データの可視化のためのライブラリです。sklearn.datasets: scikit-learnからデータセットをロードするためのモジュールです。sklearn.model_selection: データセットをトレーニングセットとテストセットに分割するためのモジュールです。sklearn.linear_model: 線形回帰モデルを作成するためのモジュールです。sklearn.metrics: モデルの評価指標を計算するためのモジュールです。
2. データのロード:
datasets.load_diabetes(): 糖尿病データセットをロードします。X: データセットからBMI(体格指数)という特徴量を取り出します。y: データセットから対応する血糖値(目標値)を取り出します。
3. データの分割:
train_test_split(): データセットをトレーニングセットとテストセットに分割します。テストセットはモデルの評価に使用されます。
4. モデルのトレーニング:
LinearRegression(): 線形回帰モデルを作成します。fit(): トレーニングデータを使用してモデルをトレーニングします。
5. テストデータでの予測:
predict(): テストデータを使用して血糖値を予測します。
6. モデル評価:
mean_squared_error(): 平均二乗誤差(MSE)を計算します。これはモデルの予測と実際の値の誤差の平均の二乗を示します。r2_score(): 決定係数(R-squared)を計算します。これはモデルがデータをどれだけ良く説明できるかを示します。
7. グラフ化:
plt.scatter(): テストデータの実際の血糖値データを散布図としてプロットします。plt.plot(): モデルによる予測を青い線でプロットします。- グラフのタイトル、軸ラベル、および評価指標の表示を設定します。
8. plt.show(): グラフを表示します。
このプログラムは、単一の特徴量(BMI)を使用して血糖値を予測する単純な線形回帰モデルを示しています。
グラフを通じて、モデルがデータにどの程度適合しているかや、評価指標を通じてモデルの性能を評価できます。
グラフ解説
このグラフは、糖尿病データセットを用いて作成されたもので、血糖値の予測に関連するものです。
以下はグラフの詳細な説明です。
1. データポイント:
グラフ上に表示された黒い点は、実際のデータポイントを表しています。
それぞれの点は、BMI(Body Mass Index、体格指数)と血糖値の組み合わせを示しています。
糖尿病患者のデータポイントです。
2. 予測線:
青い直線は、線形回帰モデルによって予測された血糖値を表しています。
この線は、BMIと血糖値の間の関係を表現しており、回帰モデルがデータを元に作成した予測です。
3. X軸とY軸:
X軸はBMIを表しており、BMIが横軸に沿って変化すると、予測される血糖値が変化することが示されています。
Y軸は血糖値を表しており、縦軸に沿って実際の血糖値の値が示されています。
4. 評価指標:
グラフの下部には、モデルの評価指標が表示されています。
“Mean Squared Error (MSE)” は平均二乗誤差を示し、モデルの予測と実際の値の差の平均の二乗を表します。
“R-squared” は決定係数を示し、モデルがデータをどれだけよく説明できるかを示します。
これらの評価指標は、モデルの性能を評価するために使用されます。
線形回帰モデルは、BMIと血糖値の間の線形関係を仮定しており、データに基づいてこの関係を学習しています。
グラフを通じて、モデルがデータにどれだけ適合しているか、そしてBMIから血糖値を予測するためのモデルの有用性を視覚的に評価できます。