
異常検出
異常検出の例として、シンプルなユースケースとして1次元のデータで異常を検出することを考えてみましょう。
以下は、正規分布に従うデータに対して異常を検出する例です。
1 | import numpy as np |
このコードでは、正規分布に従うデータに3つの異常値を追加しています。
Isolation Forestアルゴリズムを使用して異常検出を行い、異常スコアをプロットしています。
異常スコアが閾値を超えるデータポイントは、異常として検出されたとみなすことができます。
なお、実際のデータではより多くの特徴量や高次元データを扱うことになるため、適切なデータの前処理やモデルの調整が必要です。
また、異常の定義や異常値の割合に応じてcontaminationパラメータを調整する必要があります。
ソースコード解説
以下にコードの各部分の詳細な説明を行います。
1. モジュールのインポート:
最初の数行では、必要なライブラリとモジュールをインポートしています。
numpy(npとしてエイリアス): 数値計算用のライブラリ。matplotlib.pyplot(pltとしてエイリアス): データの可視化用のライブラリ。IsolationForestクラス: Scikit-learnの異常検出アルゴリズムであるIsolation Forestを提供するクラス。
2. データの生成と準備:
normal_data: 正規分布に従うランダムなデータを生成しています。
平均 (loc) は0、標準偏差 (scale) は1で、サイズは1000です。anomalies: 異常値の配列を手動で定義しています。
3. データと異常値のプロット:
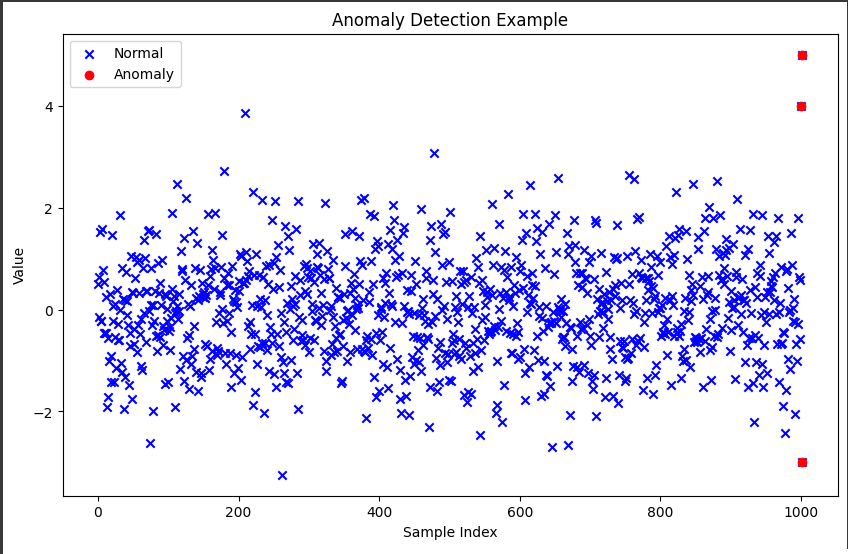
plt.scatter: データと異常値をプロットしています。
青い「x」マーカーは正常なデータポイントを示し、赤い「o」マーカーは異常値を示します。
X軸はサンプルのインデックス、Y軸は値です。
4. Isolation Forestモデルの構築と異常検出:
IsolationForestのインスタンスを作成しています。
contaminationパラメータは異常値の割合を指定します。
random_stateは乱数のシードを固定します。model.fit: モデルをデータに適合させます。
5. データの異常スコアを予測:
model.decision_function: データポイントの異常スコアを計算します。
異常スコアは、モデルがデータポイントを異常とみなす確信度の尺度です。
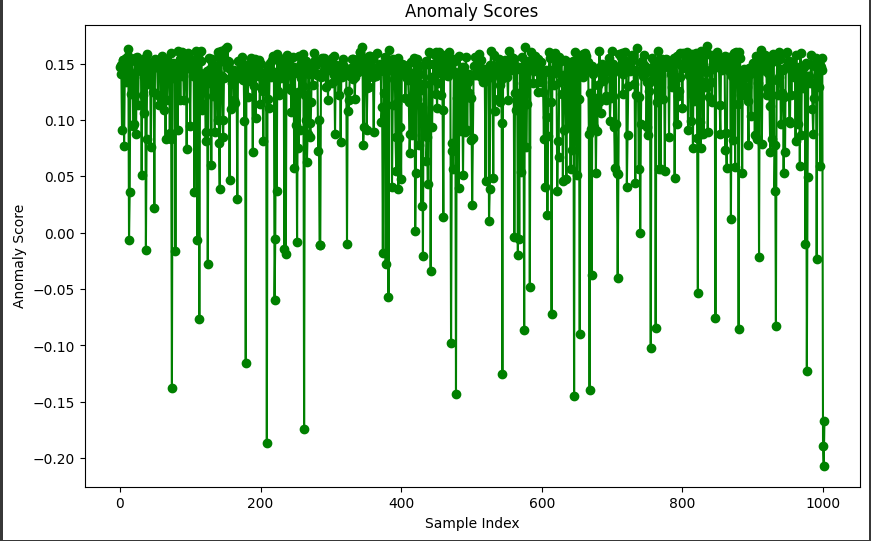
6. 異常スコアのプロット:
plt.plot: データポイントの異常スコアをプロットしています。
異常スコアが低いほど正常、高いほど異常と判断される可能性が高くなります。
X軸はサンプルのインデックス、Y軸は異常スコアです。
このコードは、Isolation Forestアルゴリズムを使用して異常検出を行い、異常スコアをプロットして視覚化するサンプルです。
ただし、実際のケースではデータの前処理、ハイパーパラメータの調整、適切なモデルの選択などが必要です。
結果解説
異常検出の結果として表示される2つのグラフについて、詳しく説明します。
1. データと異常値のプロット:
このグラフは、元のデータと追加した異常値を含むデータポイントを表示しています。
以下の要素に注意してください:
- 青い「x」マーカー:
正常なデータポイントを表しています。これらは正規分布に従うランダムなデータです。 - 赤い「o」マーカー:
異常値を表しています。これらはわざとデータに追加された異常な値です。
このプロットは、異常検出のタスクを視覚的に理解するのに役立ちます。
異常値が通常のデータポイントからどれだけ外れているかが分かります。
2. 異常スコアのプロット:
このグラフは、Isolation Forestアルゴリズムによって計算された異常スコアを示しています。
以下の要素に注意してください:
- 縦軸 (Y軸): 異常スコアを表しています。
スコアが低いほどデータポイントは正常、高いほど異常と判断された可能性が高いです。 - 横軸 (X軸): データポイントのインデックスを表しています。
グリーンの線で表されたプロットは、各データポイントの異常スコアを示しています。
異常スコアが閾値を超えるデータポイントは、異常として検出されたとみなされます。
これらのグラフは、異常検出のプロセスを理解し、異常検出アルゴリズムのパフォーマンスを評価する際に役立ちます。
異常スコアを基にして異常を検出するため、グラフから異常値がどれだけ明確に特定されているかを確認することが重要です。