
ユーザー行動予測
ユーザー行動予測の例題として、「オンラインショッピングサイトのユーザーが特定の商品を購入するかどうかを予測する」という問題を取り上げます。
これは二値分類の問題であり、ユーザーの属性や過去の行動履歴を元に、購入行動の有無を予測することが目標です。
ここでは、サンプルとしてランダムに生成したデータを使ってscikit-learnのロジスティック回帰モデルを使用して予測を行います。
まずは必要なライブラリをインポートし、データを生成しましょう。
1 | import numpy as np |
次に、ロジスティック回帰モデルを学習させ、テストデータでの予測を行います。
1 | # ロジスティック回帰モデルの学習と予測 |
予測の性能を評価するために、正解率や混同行列を計算してみましょう。
1 | # 正解率の計算 |
最後に、結果をグラフ化してみましょう。データ点を散布図で表示し、モデルが予測した境界線を描画します。
1 | # グラフ化 |
このコードは、ユーザー行動予測のためのロジスティック回帰モデルを使用して、属性情報を元に購入行動の有無を予測し、その結果をグラフで視覚化しています。
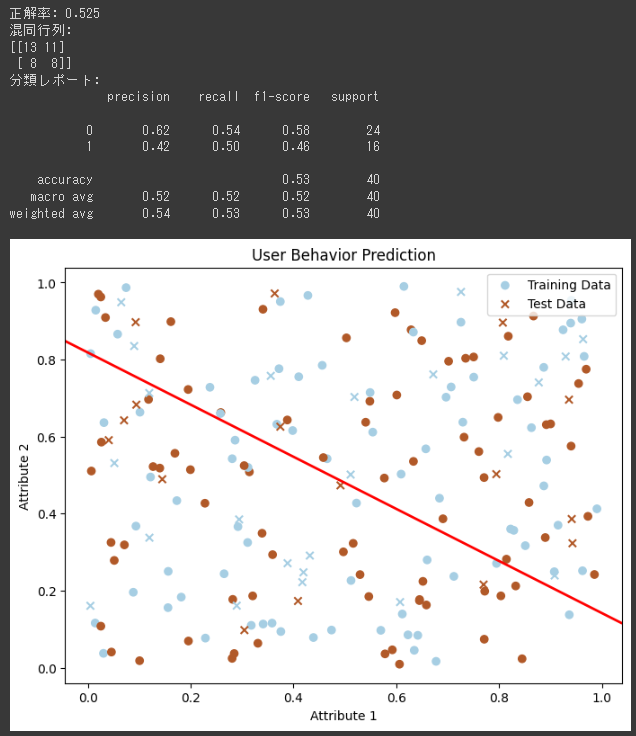
[実行結果]
ソースコード解説
このソースコードは、ユーザー行動予測の問題を解くために、ランダムに生成したデータを使ってロジスティック回帰モデルを学習し、その性能を評価するプログラムです。
以下に各部分の詳細を説明します。
1. データの生成:
ユーザー行動予測のためのデータをランダムに生成します。np.random.rand関数を使って、2つの属性を持つ200個のサンプル (num_samples = 200) を生成し、それぞれのサンプルに対して0または1のランダムなラベルを割り当てます。user_attributesは2つの属性を持つ特徴量の行列であり、user_behaviorは0または1のラベルを持つベクトルです。
2. データの学習とテストへの分割:
train_test_split関数を使って、生成したデータを学習データ (X_train, y_train) とテストデータ (X_test, y_test) に分割します。
ここでは、全体の20%をテストデータとして使用しています。
3. ロジスティック回帰モデルの学習と予測:
LogisticRegressionクラスを用いて、ロジスティック回帰モデルを作成し、学習データを使ってモデルを学習します。fitメソッドによりモデルが学習されます。
その後、テストデータを使ってモデルの予測を行い、予測結果をy_predに格納します。
4. 正解率の計算:
accuracy_score関数を使って、モデルの予測結果と真のラベル (y_test) を比較し、正解率を計算します。
正解率は全てのサンプルのうち、正しく予測できたサンプルの割合を示します。
5. 混同行列の表示:
confusion_matrix関数を使って、モデルの予測結果と真のラベルを元に混同行列を計算します。
混同行列は、予測がどれだけ正確であるかを評価する際に有用な情報を提供します。
6. 分類レポートの表示:
classification_report関数を使って、適合率 (precision)、再現率 (recall)、F1スコア (F1-score)、およびサポート (support) を含む分類レポートを表示します。
これらの指標は、各クラスごとにモデルの性能を評価するために使われます。
7. グラフ化:
matplotlibを使って、学習データとテストデータの散布図を表示します。
また、ロジスティック回帰モデルが予測した境界線を赤色で描画しています。
これにより、モデルがどのようにデータを分類しているかを視覚的に理解できます。
最終的に、このコードはランダムに生成したデータを使ってロジスティック回帰モデルを学習し、モデルの性能を評価するための各種指標を表示し、データの可視化を行っています。
これにより、ユーザー行動予測モデルの性能を把握することができます。
結果解説
以下にそれぞれの評価指標について詳しく説明します。
1. 正解率 (Accuracy):
正解率は、全てのサンプルのうち、正しく分類されたサンプルの割合を示します。
この場合の正解率は0.525 (または 52.5%) です。正解率が高いほど、モデルの予測精度が高いことを意味します。
ただし、この値だけでモデルの性能を判断するのは注意が必要で、他の指標と併せて評価することが重要です。
2. 混同行列 (Confusion Matrix):
混同行列は、モデルが予測したクラスと真のクラスのペアを示す行列です。
この混同行列は2x2の行列で、以下のように解釈されます:
- 左上のセル (True Negative): 13個のサンプルがクラス0と予測され、実際にクラス0であった。
- 右上のセル (False Positive): 11個のサンプルがクラス1と予測され、実際はクラス0であった。
- 左下のセル (False Negative): 8個のサンプルがクラス0と予測され、実際はクラス1であった。
- 右下のセル (True Positive): 8個のサンプルがクラス1と予測され、実際にクラス1であった。
3. 分類レポート (Classification Report):
分類レポートは、クラスごとの適合率 (precision)、再現率 (recall)、F1スコア (F1-score)、およびサポート (support) を示す表です。
適合率 (Precision):
正しく分類された陽性サンプル (True Positive) の割合を示します。
クラス0の適合率は0.62であり、クラス1の適合率は0.42です。
適合率が高いほど、陽性と予測されたサンプルが実際に陽性である確率が高いことを意味します。再現率 (Recall):
実際に陽性のサンプルのうち、正しく分類された割合を示します。
クラス0の再現率は0.54であり、クラス1の再現率は0.50です。
再現率が高いほど、実際に陽性であるサンプルを見逃さずに予測できることを意味します。F1スコア (F1-score):
適合率と再現率の調和平均です。
F1スコアは、適合率と再現率のバランスを取る指標として使われます。
クラス0のF1スコアは0.58であり、クラス1のF1スコアは0.46です。サポート (Support):
各クラスに属するサンプルの数を示します。
クラス0には24個のサンプルがあり、クラス1には16個のサンプルがあります。
総合的に見ると、このユーザー行動予測モデルは、精度やF1スコアなどの評価指標が比較的低いため、改善の余地があると言えます。
モデルの性能を向上させるためには、より適切な特徴量の選択やモデルの調整、データの前処理などが必要かもしれません。