
顧客離反予測(チャーン予測)
顧客離反予測(チャーン予測)の例題として、以下のようなシナリオを考えます:
あるテレコム会社があり、顧客の情報と過去の利用データが得られています。
これを使って、顧客が離反するかどうかを予測し、リテンション戦略を立てたいとします。
scikit-learnを使ってロジスティック回帰モデルを構築し、結果をグラフ化してみましょう。
1 | import numpy as np |
上記のコードでは、ダミーデータを作成してロジスティック回帰モデルを構築し、ROC曲線をプロットしています。
ROC曲線はモデルの性能を評価する際によく用いられる指標で、AUC (Area Under the Curve) の値が高いほど優れた予測モデルと言えます。
[実行結果]
ソースコード解説
上記のコードは、ロジスティック回帰モデルを使用して顧客離反予測(チャーン予測)を行い、その結果をROC曲線を用いて可視化しています。
以下にコードの詳細を説明します:
ダミーデータを生成する関数
generate_dummy_data:- この関数は仮想的なデータを生成するためのもので、乱数を使って顧客の年齢 (
Age)、利用期間 (UsageMonths)、月間支出 (MonthlyExpense)、および離反したかどうかを表すターゲット変数 (Churn) を作成します。
- この関数は仮想的なデータを生成するためのもので、乱数を使って顧客の年齢 (
ダミーデータの生成:
generate_dummy_data()関数を呼び出して、ダミーデータを生成します。このデータはdataという名前のPandas DataFrameに保存されます。
特徴量とターゲットの分割:
X = data.drop('Churn', axis=1)で特徴量 (Age,UsageMonths,MonthlyExpense) を取得します。y = data['Churn']でターゲット変数Churn(離反したかどうかを表すラベル)を取得します。
訓練データとテストデータの分割:
train_test_split()を使ってデータを訓練データとテストデータに分割します。テストデータは全体の20%に設定されており、random_state=42で乱数シードを固定して再現性を保証しています。
ロジスティック回帰モデルの構築と学習:
LogisticRegression()を使用してロジスティック回帰モデルを初期化し、fit()メソッドで訓練データに適合させます。
テストデータを用いた予測:
predict()メソッドを使用して、テストデータの特徴量を用いて離反の予測を行います。predict_proba()メソッドを使用して、各テストサンプルがクラス1(離反)に属する確率を取得します。
ROC曲線のプロットと結果の可視化:
roc_curve()関数を用いて、予測確率と真のターゲット値を用いてROC曲線のデータを取得します。roc_auc_score()関数を用いて、ROC曲線の下の面積 (AUC) を計算します。plt.figure()でグラフのサイズを設定し、plt.plot()を用いてROC曲線を描画します。plt.plot([0, 1], [0, 1], color='gray', lw=2, linestyle='--')は対角線を描画し、ランダムな予測の場合の参考として用います。- ラベル、軸の範囲、タイトルなどのグラフの詳細設定を行います。
- 最後に
plt.show()でグラフを表示します。
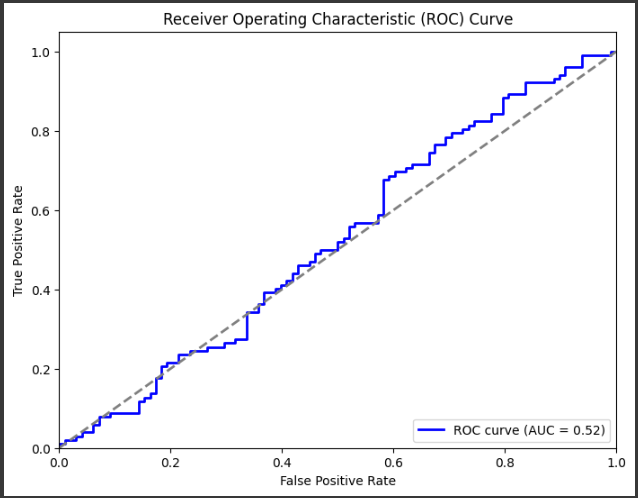
結果として、ROC曲線が表示されます。
この曲線は、モデルの性能評価に使用され、AUCスコアが曲線下の面積を示します。
AUCが高いほど、モデルの性能が良いとされます。
結果解説
表示されるグラフは「Receiver Operating Characteristic (ROC) Curve(受信者動作特性曲線)」です。
ROC曲線は、二値分類モデル(ここではロジスティック回帰モデル)の性能評価に用いられるグラフで、以下の要素で構成されています:
X軸(横軸): False Positive Rate (FPR)
- FPRは、実際には陰性(クラス0)であるもののうち、モデルが陽性(クラス1)と誤って予測したサンプルの割合を示します。計算式は FPR = FP / (FP + TN) であり、FPは偽陽性の数、TNは真陰性の数です。
Y軸(縦軸): True Positive Rate (TPR) または Recall
- TPRは、実際には陽性(クラス1)であるもののうち、モデルが陽性と正しく予測したサンプルの割合を示します。計算式は TPR = TP / (TP + FN) であり、TPは真陽性の数、FNは偽陰性の数です。
ROC曲線の解釈:
- 曲線の左下に近いほど、FPRが低く、真陰性率が高くなりますが、偽陽性率が高くなる傾向があります。
- 曲線の右上に近いほど、FPRが高く、真陽性率が高くなりますが、偽陰性率が低くなる傾向があります。
AUC (Area Under the Curve):
- ROC曲線の下の面積をAUCと呼びます。AUCは0から1の間の値を取り、モデルの性能を評価する指標です。
AUCが1に近いほど、モデルの性能が優れていると言えます。
このグラフを見ることで、モデルの性能がどれくらい優れているかが把握できます。
AUCが高いほど、モデルの予測精度が高いと言えます。ROC曲線が左上に近いほど、優れた分類モデルと言えます。