
クロスセル予測
クロスセル予測は、顧客がある商品を購入した後に他の商品を購入する可能性を予測するための手法です。
ここでは、scikit-learnを使用して、顧客がある商品を購入した後に他の商品を購入する可能性を予測する簡単な例を示します。
1.ライブラリのインポート
これらのライブラリは、データの操作、可視化、モデルの訓練と評価に必要です。
1 | import numpy as np |
2.データの生成
ここでは、500人の顧客が商品Aを購入し、そのうち200人が商品Bも購入しているというデータを生成しています。
Xは顧客の特徴量を表し、yは商品Bを購入したかどうかを表します。
1 | # 商品Aを購入した顧客の数 |
3.データの分割
データを訓練データとテストデータに分割します。
訓練データはモデルの学習に、テストデータはモデルの性能評価に使用します。
1 | # データを訓練データとテストデータに分割 |
4.モデルの訓練
ランダムフォレスト分類器を使用してモデルを訓練します。
ランダムフォレストは、複数の決定木を組み合わせて予測を行うアルゴリズムです。
1 | # ランダムフォレスト分類器のインスタンスを作成 |
5.予測と評価
訓練したモデルを使用してテストデータのクロスセルを予測し、混同行列を計算します。
混同行列は、モデルの性能を評価するための表です。
1 | # テストデータのクロスセルを予測 |
6.結果の可視化
混同行列をヒートマップとして表示します。
これにより、モデルの性能を視覚的に理解することができます。
1 | # 混同行列を表示 |
[実行結果]
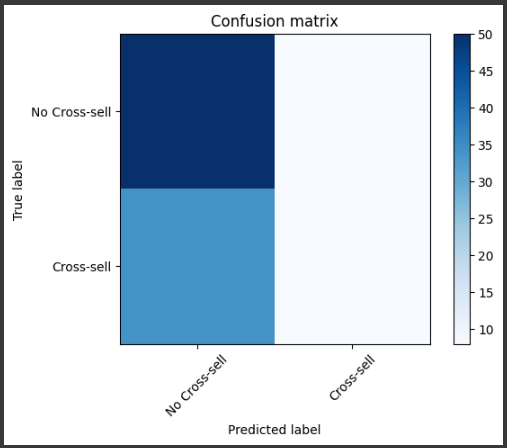
実際の問題では、顧客の特徴量をより詳細に把握するために、購入履歴や顧客のデモグラフィック情報など、さまざまなデータを使用することがあります。
また、モデルの性能を向上させるために、パラメータのチューニングや他の機械学習アルゴリズムの使用もあります。
混同行列(Confusion Matrix)
モデルの予測結果は、混同行列(Confusion Matrix)によって表現されます。
混同行列は、実際のクロスセルのラベルと予測されたクロスセルのラベルを比較し、それらの関係を可視化します。
混同行列は4つのセルで構成されます:
- 真陽性(True Positive; TP):
実際のラベルが「クロスセルあり」であり、予測も「クロスセルあり」の場合。 - 真陰性(True Negative; TN):
実際のラベルが「クロスセルなし」であり、予測も「クロスセルなし」の場合。 - 偽陽性(False Positive; FP):
実際のラベルが「クロスセルなし」であり、予測が「クロスセルあり」となった場合。 - 偽陰性(False Negative; FN):
実際のラベルが「クロスセルあり」であり、予測が「クロスセルなし」となった場合。
混同行列の各セルには、実際のデータポイントの数が表示されます。
モデルが正しく予測した場合は真陽性(TP)や真陰性(TN)の数が高くなり、誤った予測があった場合は偽陽性(FP)や偽陰性(FN)の数が増えます。
この例では、混同行列が表示されると、x軸が予測ラベル、y軸が実際のラベルであり、それぞれのセルに該当するデータポイントの数が表示されます。
これにより、モデルの予測結果の正確さやエラーの傾向を評価することができます。
また、混同行列から算出される指標として、精度(Accuracy)、再現率(Recall)、適合率(Precision)、F1スコア(F1 Score)などがあります。
これらの指標は、モデルの性能評価や比較に使用されます。