Dash + Dask
Daskは、メモリにのらないような大きなデータを扱う際によく使われるライブラリです。
主な特徴は、以下の通りです。
- 並列処理・分散処理などを簡単に扱える。
- Pythonでよく使われるライブラリ(NumPy、Pandas、Scikit-Learnなど)とかなり近いインターフェイスを提供している。
- データを全てメモリに乗せず、ある単位でメモリに乗せたりして計算するので、通常Pandasなどでメモリに乗り切らない大きなデータセットでも扱える。
サンプル
DashでDaskを使った簡単なサンプルを作成します。
下記のファイルをダウンロードして、ソースコードと同じ位置に配置しておきます。
[ソースコード]
1 | import dash |
読み込んだ元のデータフレーム(df) をフィルタリングして、filt_df を作成しています。(filter_df関数)
元のデータ(df) は Dask DataFrammeでしたが、compute()メソッドで Pandas DataFrame に変換されています。(11行目)
この処理により、よりコンパクトなメモリ内オブジェクト(filt_df)を利用して図を作成することができます。
Dashを使うことにより計算コストの高い繰り返しを最小限に抑えることができます。
[ブラウザで表示]
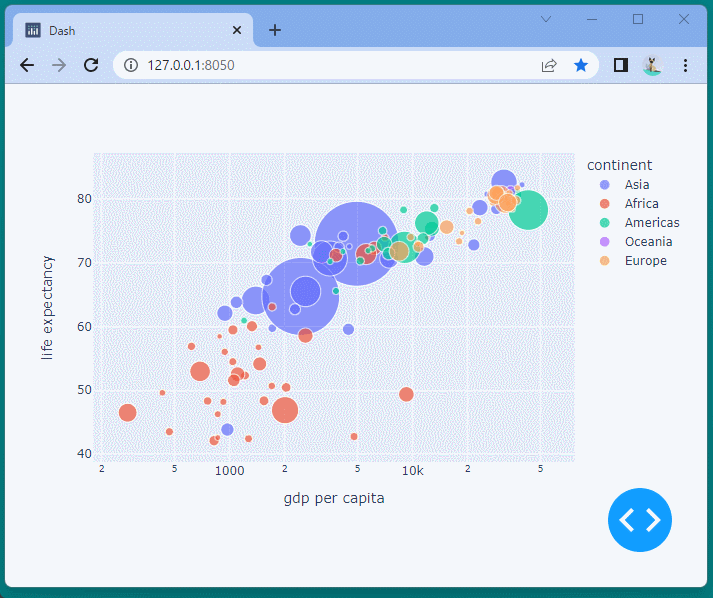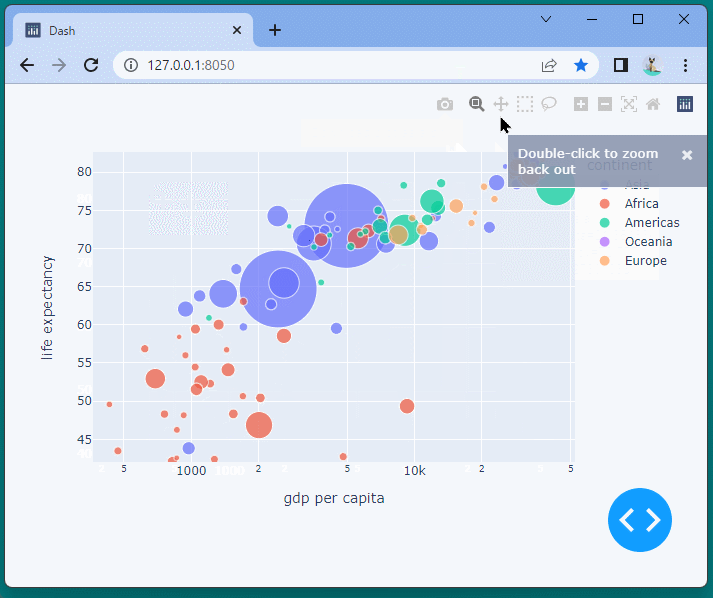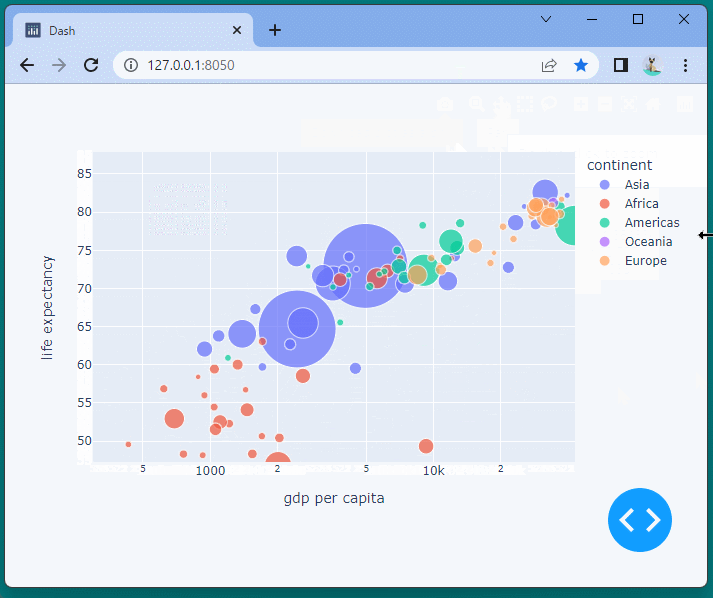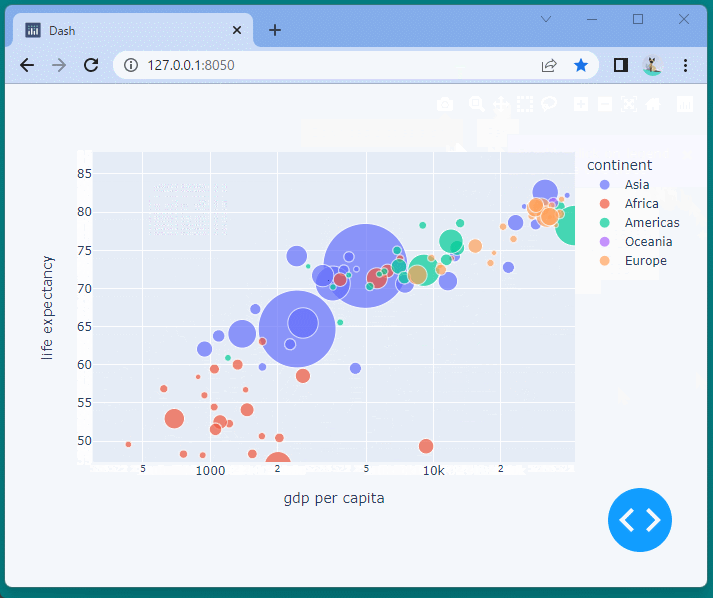
平均寿命とGDPを表したバブルチャートを表示することができました。
指定した範囲を拡大表示したり、移動したり、凡例をクリックしデータの表示と非表示を切り替えたりすることが可能です。