PyCaretでのハイパーパラメータチューニングを行ってみます。
回帰モデル作成
まずランダムフォレストモデルを作成します。
create_model関数にランダムフォレストのID‘rf’を渡してモデルを作成しています。
fold引数には10を設定しており、データを10分割して10回交差検証を行います。
[Google Colaboratory]
1 | rf = create_model('rf', fold = 10) |
[実行結果]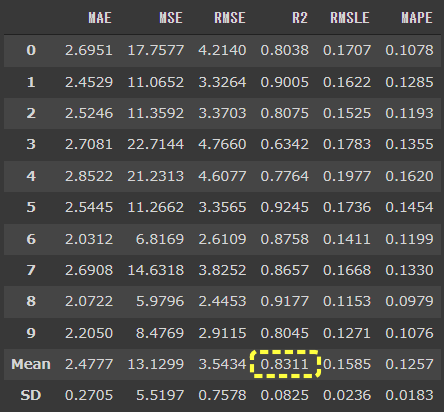
10回分の交差検証結果と合わせて、平均値(Mean)と標準偏差(SD)もあわせて結果に表示されています。
R2の平均は0.8311となっています。
ハイパーパラメータチューニング
ハイパーパラメータの最適化を実施します。
tune_model関数の第一引数にモデル(作成したランダムフォレストモデル)を指定します。
optimize引数には対象となる指標を指定します。今回はR2を設定しています。
[Google Colaboratory]
1 | tuned_rf = tune_model(rf, optimize = "r2", fold = 10) |
[実行結果]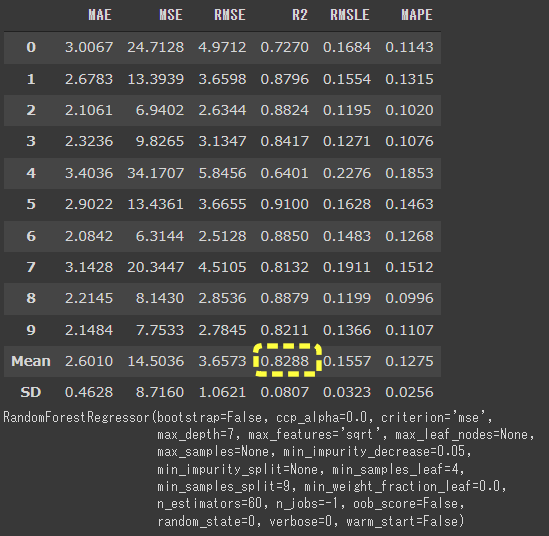
R2の平均が0.8311から0.8288に下がってしまいました。
次にn_iter引数を追加して50を指定して実行します。(n_iterのデフォルト値は10)
PyCaretではチューニングにランダムグリッド検索が採用されており、n_iterでパラメータ探索の繰り返し回数を指定することができます。
[Google Colaboratory]
1 | tuned_rf = tune_model(rf, optimize = "r2", fold = 10, n_iter = 50) |
[実行結果]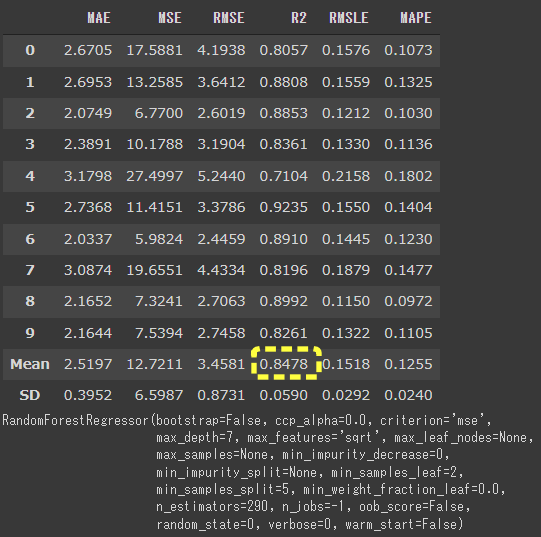
R2の平均が0.8311から0.8478に上がりました。
前回より精度は上がりましたが、繰り返し回数を増やしたため処理時間は長くなりました。