SHAP
SHAPは、学習済みモデルにおいて各説明変数が予測値にどのような影響を与えたかを貢献度として定義して算出するモデルです。
各データごとに結果を出力し、可視化することができます。
前準備
前準備として、ボストンデータセットを用いた回帰モデル(決定木)を作成し、予測結果を確認します。
[Google Colaboratory]
1 | import pandas as pd |
[実行結果]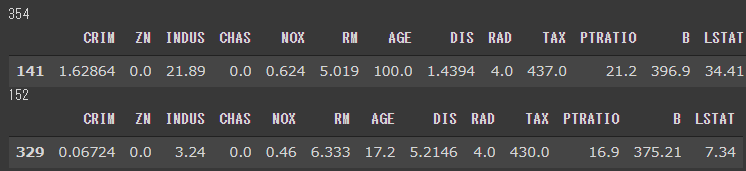
以上で、回帰系の決定木モデルが作成できました。
重要度
作成したモデルの説明変数ごとに重要度を表示します。
[Google Colaboratory]
1 | import matplotlib.pyplot as plt |
feature_importances_を参照し、説明変数ごとの重要度を取得しています。(5行目)
[実行結果]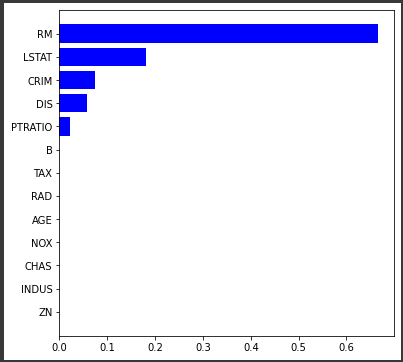
このモデルでは、RM、LSTATなどの重要度が高く、予測に強く影響していることが確認できます。
予測値の算出
予測値を算出します。
[Google Colaboratory]
1 | X_test_pred = X_test.copy() |
テストデータで予測値を算出し、結果を説明変数とマージしています。(2行目)
重要度の高い説明変数の上位5項目と、予測値(pred)を表示しています。(3行目)
[実行結果]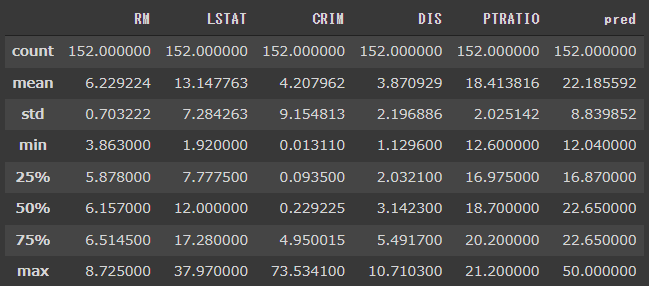
RMは8.7付近が最大値となっており、predの最大は50になっています。
予測値の表示
最も重要度の高かった説明変数であるRMでソートして、結果を確認してみます。
[Google Colaboratory]
1 | X_test_pred.sort_values("RM") |
[実行結果]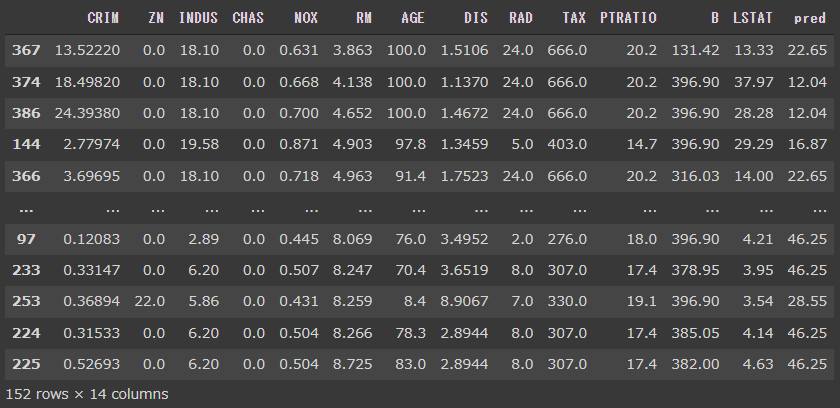
predの最大値が50だったので、RMが高いほどpredも高く、RMが低いほどpredも低く出ている傾向が見られます。
2番目に重要度が高かったLSTATはその逆で、LSTATが高いとpredは低く、LSTATが低ければpredが高くなっているようです。
このようにfeature_importances_は、モデル作成時にどのような説明変数が重要であるかを知るために大局的な指標となります。
一方SHAPは、作成したモデルの各説変数がどのように予測に寄与してしるかを知るための局所的な指標となります。
次回はSHAPを実装して予測結果を確認していきます。