ランダムサーチ
ランダムサーチは決められた候補値のランダムな組み合わせを決められた回数だけ検証し、その限られた回数の中で最も良い評価を得たパラメータの組み合わせを導き出す手法です。
グリッドサーチの欠点である計算コストの高さを検証回数を制限することで解消した一方、パラメータ全ての組み合わせを検証するわけではないので、必ずしも最適な組み合わせを見つけることができない点が特徴になります。
ランダムサーチ用のモデル構築
ランダムサーチを行うには、scikit-learnのRandomizedSearchCVクラスを使用します。
[Google Colaboratory]
1 | xgb_reg_random = xgb.XGBRegressor() |
n_iterにはランダムサーチの検証回数を指定します。(12行目)
[実行結果(一部)]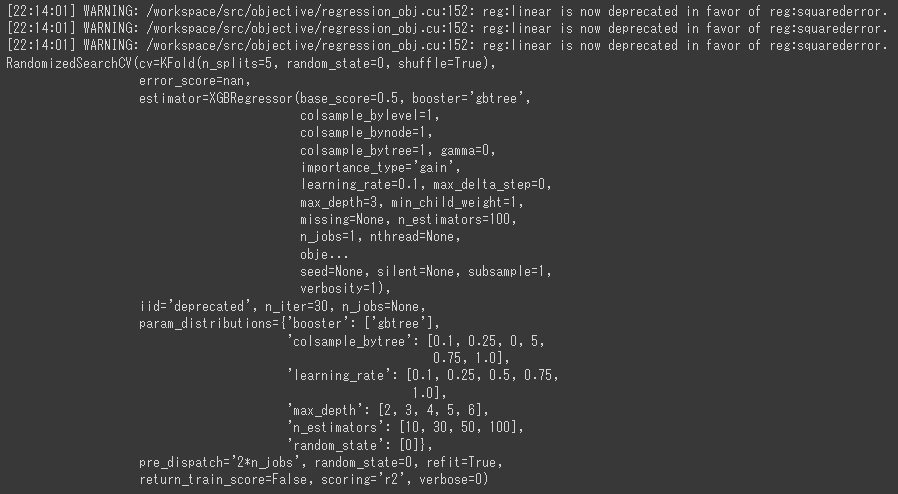
グリッドサーチよりもかなり速く処理を完了させることができました。
ランダムサーチの結果
ランダムサーチで最も評価が高かった組み合わせとそのスコアを出力します。
[Google Colaboratory]
1 | print(random.best_params_) |
[実行結果]
グリッドサーチではスコアが0.89でしたが、ランダムサーチではスコアが0.88と少し精度が落ちてしまっています。
今回のランダムサーチは最適なパターンまでたどり着かなかったということになります。
テストデータでの評価
最後に、テストデータを使った評価を行います。
[Google Colaboratory]
1 | y_test_pred = random.predict(X_test) |
[実行結果]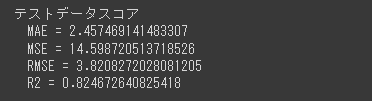
R2スコアが0.82以上となっており、グリッドサーチの0.80より良い結果となります。
最終評価にはパラメータチューニングに関与していないテストデータを使用しているので、グリッドサーチよりランダムサーチの方が良い結果となることは十分にありえます。
この点を踏まえて、どの方法でパラメータチューニングを行うかはケースによって使い分ける必要があります。