決定木の深さを定義するハイパーパラメータであるmax_depthを変更します。
深さの変更 (max_depth=5)
決定木の深さ(max_depth)を5に変更してみます。
[Google Colaboratory]
1 | tree_reg_depth_5 = DecisionTreeRegressor(max_depth=5, random_state=0).fit(X_train,y_train) |
次に予測値を出力し、残差プロットで可視化します。
[Google Colaboratory]
1 | y_train_pred = tree_reg_depth_5.predict(X_train) |
[実行結果]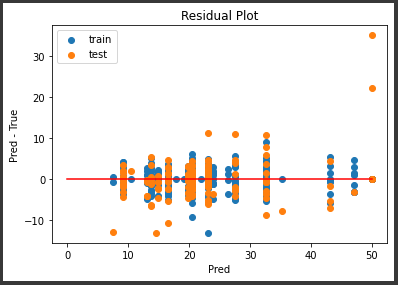
深さを5に変更したことにより、誤差のばらつきが少し小さくなりました。
精度評価スコア (max_depth=5)
精度評価スコアを表示します。
[Google Colaboratory]
1 | print("訓練データスコア") |
[実行結果]
テストデータのR2スコアが0.7となり、精度が改善しました。
しかし、訓練データのR2スコアも0.85から0.92と上昇しています。
このように決定木の深さを深くするとモデルの精度が上がる一方、訓練データに過度に適合する過学習のリスクも上がってしまいます。
深さの変更 (max_depth=20)
今度は、決定木の深さ(max_depth)を20に変更してみます。
[Google Colaboratory]
1 | tree_reg_depth_20 = DecisionTreeRegressor(max_depth=20, random_state=0).fit(X_train,y_train) |
[実行結果]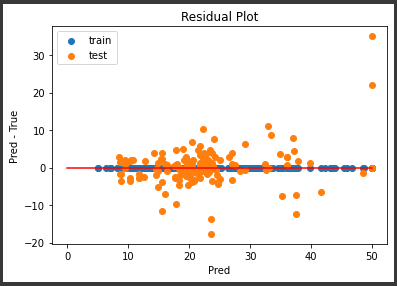
精度評価スコア (max_depth=20)
精度評価スコアを表示します。
[Google Colaboratory]
1 | print("訓練データスコア") |
[実行結果]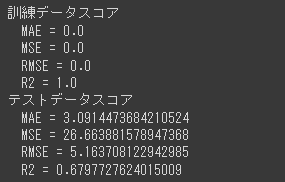
訓練データのR2スコアは1.0となり完全に適合していますが、テストデータのR2スコアは深さ5のときよりも下がっています。
これは過学習に陥っていると判断できます。