構築した重回帰モデルの重みと切片を確認します。
重みと切片
重みと切片を表示するコードは次のようになります。
[Google Colaboratory]
1 | for i, (col, coef) in enumerate(zip(boston.feature_names, multi_reg.coef_[0])): |
wの値が大きいものほど、モデルへの貢献度が高い変数です。
[実行結果]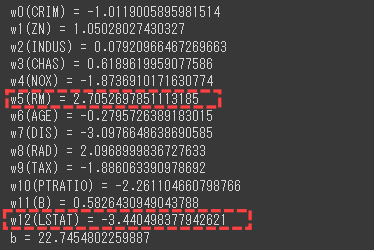
参考までに以前作成した相関係数のヒートマップを表示します。
[相関係数のヒートマップ]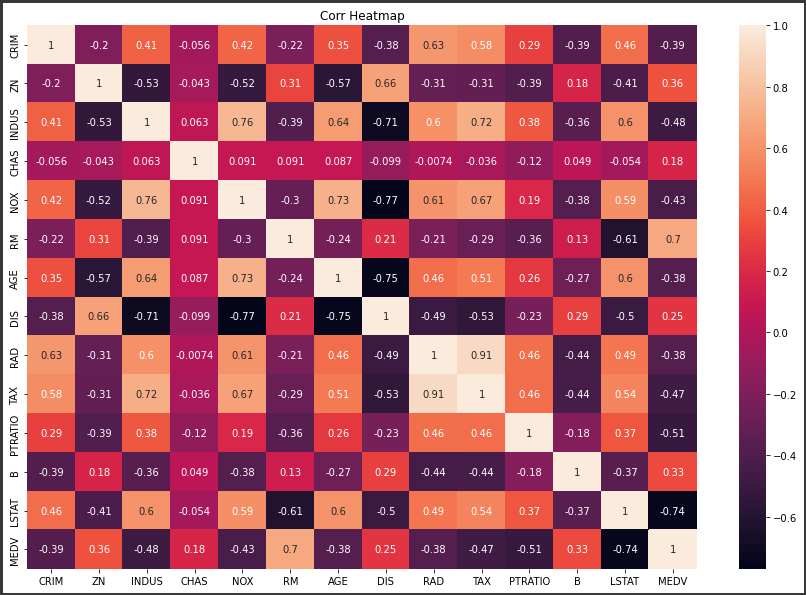
RMやLSTATなど、目的変数と相関の大きい変数の重みが比較的大きいことが分かります。
今回の精度評価スコアからは過学習の傾向は見られませんでしたが、過学習が起きている兆候の1つに説明変数の重みが大きいことが挙げられます。
そして過学習のリスクを減らすには、説明変数の重みを小さくする処理が重要となります。
次回の回帰モデルでは、過学習を抑えるために説明変数の重みが大きくならないように制限を行います。