前回準備したボストン住宅価格データの概要を見ていきます。
ボストンの住宅価格データの概要
pandasのdescribeメソッドを使ってデータの概要を確認することができます。
[Google Colaboratory]
1 | df.describe() |
[実行結果]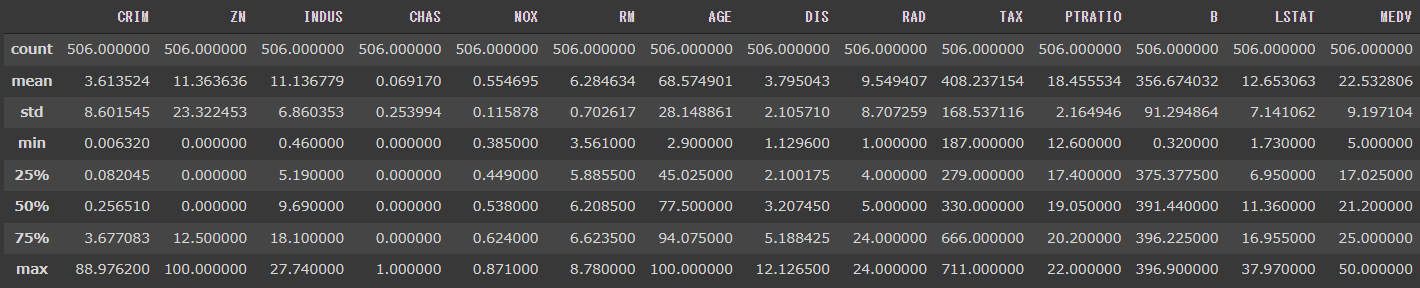
count(データ数)やmean(平均値)など代表的な数値が表示されました。
この数値から次のようなことが分かります。
- 前回確認したデータ数と、各変数のcount(データ数)が一致しているので、欠損値はない。
- CRIMとZNは第三四分位数と最大値に乖離があり、外れ値の存在が予想される。
もしも欠損値が含まれている場合は学習処理ができないので、除去や保管などであらかじめ対処しておく必要があります。
ヒストグラムによるばらつき確認
データのばらつきや外れ値を把握するために、ヒストグラムで表示して視覚的にデータを確認してみます。
[Google Colaboratory]
1 | import matplotlib.pyplot as plt |
[実行結果]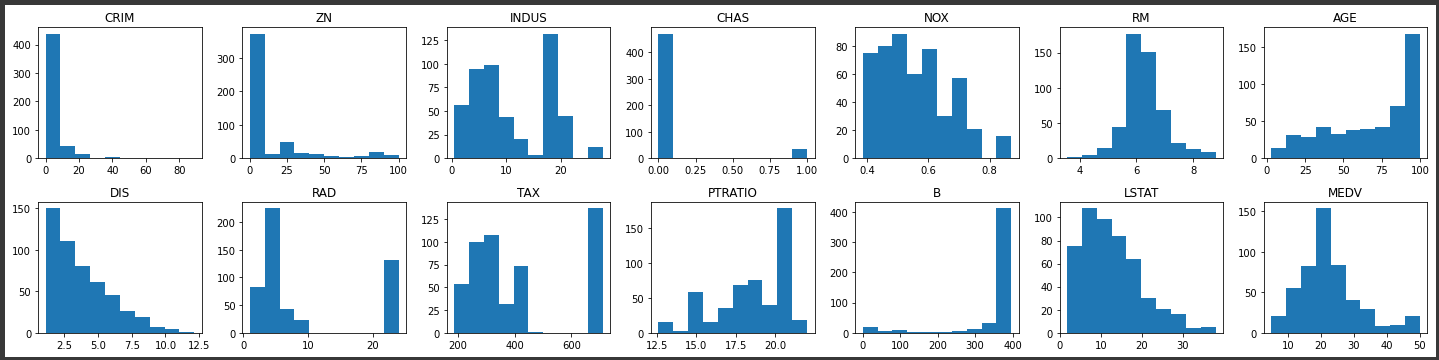
ヒストグラムから、CRIMやZNで外れ値があることが分かります。
またRMは比較的正規分布に近く、ばらつきが少ないようです。
目的変数であるMEDVも正規分布に近い形状ではありますが、一部外れ値が含まれているようです。