前回読み込んだアイリスデータを参照しk-means法でクラスタリングを行います。
クラスタ数(グループ数)
k-means法では、クラスタ数(グループ数)を指定する必要があります。
今回のデータではクラスタ数が3種類(’setosa’、’versicolor’、’virginica’)であることがあらかじめわかっているので問題ありませんが、最適なクラス数は分からないことがほとんどであり、実際の運用や評価を実施して決めることになります。
k-means法
k-means法は、各データ間での距離をもとにグループを分けていく手法です。
最初に適当なクラスタ(グループ)に分けて、クラスタの平均を用いてうまくデータが分かれるように調整していきます。
k-meansの実行
k-meansを実行します。
k-meansのモデルを生成する際のパラメータは以下の通りです。(2行目)
- n_clusters
クラスタ数。
‘setosa’、’versicolor’、’virginica’の3種類に分類するため3を指定。 - random_state
乱数シード。
固定値を指定しないと毎回結果が変わってしまう。 - init
クラスタセンター(セントロイド)の初期化方法。
基本的なk-meansの結果を得るために“random”を指定。
あとはfit関数にデータを渡すだけで、クラスタリングのモデル構築は完了です。(4行目)
[Google Colaboratory]
1 | from sklearn.cluster import KMeans |
[実行結果]
クラスタの予測結果取得
クラスタの予測結果を取得するソースコードは以下の通りです。
predict関数で予測結果を取得することができます。
[Google Colaboratory]
1 | cluster = model.predict(cls_data) |
[実行結果]
各データに対して0, 1, 2というようにクラスタリングのクラスタ番号が出力されます。
予測結果をグラフ化
予測した結果をグラフ化します。
[Google Colaboratory]
1 | cls_data["cluster"] = cluster |
[実行結果]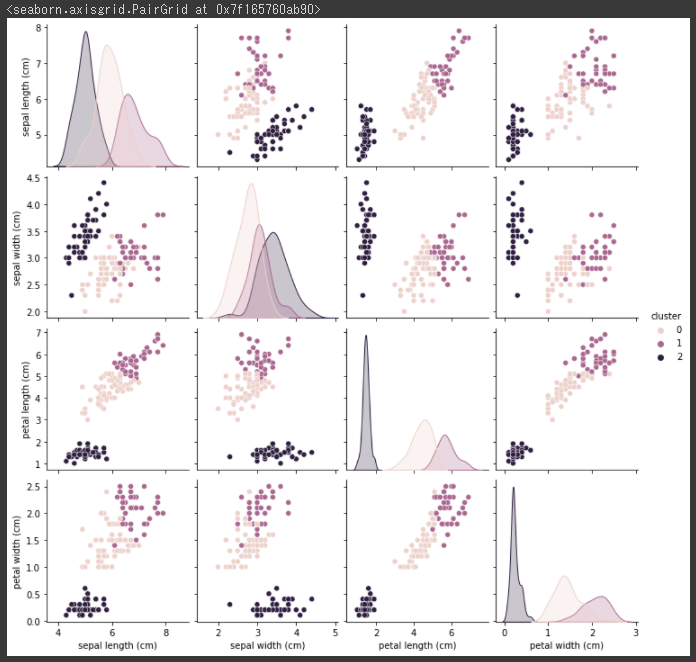
視覚的に3つのクラスタ(グループ)にまとまっていることが分かります。。
クラスタセンターの取得
model.cluster_centers_で、それぞれのクラスタの中心を取得することができます。
[Google Colaboratory]
1 | cluster_center = pd.DataFrame(model.cluster_centers_) |
[実行結果]
クラスタセンターのグラフ表示
クラスタセンターをグラフに表示してみます。
“sepal length”と”sepal width”の2変数に関して、データとクラスタセンターを表示します。
[Google Colaboratory]
1 | plt.scatter(cls_data["sepal length (cm)"], cls_data["sepal width (cm)"],c=cls_data["cluster"]) |
[実行結果]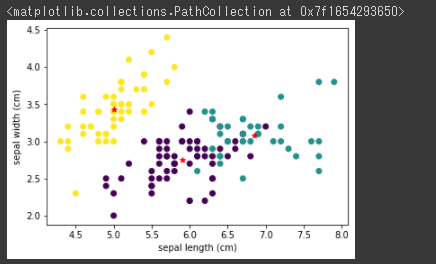
赤い★マークで表示されているのが、各クラスタを構成しているクラスターセンターの位置になります。
クラスタ番号で集計した説明変数の平均値
クラスタリングの結果を確認します。
クラスタ番号で集計を行い、説明変数の平均を表示します。
[Google Colaboratory]
1 | display(cls_data.groupby("cluster").mean().round(2)) |
[実行結果]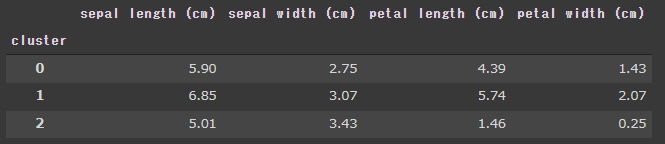
正解データとの比較
正解データと合わせて、答え合わせを行います。
確認しやすいように花の種類を設定して、花の種類で集計して平均を表示します。
[Google Colaboratory]
1 | cls_data["target"] = iris.target |
[実行結果]
cluster列にはクラスタ番号の0, 1, 2が表示されています。
4つの変数がすべて一致しているsetosaはクラスタ番号2で全て正しくクラスタ化されていることが分かります。
versicolorとvirginicaですが、4つの変数が完全に一致しているわけではありませんが、近い数字にはなっているのでそれなりにクラスタ化されているかと思います。
次回は、調整ランド指数と正解率を使ってクラスタリングの結果を評価してみます。