データをグルーピングするクラスタリングを行いたいと思います。
今回はクラスタリングを行うデータを準備し、次回はk-means法でクラスタリングを行います。
実行環境としてGoogle Colaboratoryを使います。
アイリスデータの読み込み
sklearn.datasetsに用意されているアイリスデータのデータセットを読み込みます。
アイリスとは「あやめ」という花のことで、花びら(Petal)とがくの長さ(Sepal)で種類を分けることができます。
[Google Colaboratory]
1 | import pandas as pd |
[実行結果]
データの形状は、150個のサンプルデータがあり、サンプルごとに4種類の変数があることが分かります。
アイリスデータの花の種類
アイリスデータの花の種類を確認します。
[Google Colaboratory]
1 | print(iris.target_names) |
[実行結果]
‘setosa’、’versicolor’、’virginica’という3種類があることが分かりました。
データフレームに格納
データを扱いやすくするために、データフレームに格納します。
iris.dataで4変数のデータを取得し、columnsにiris.feature_nameを代入することで、カラム名に変数を指定しています。
[Google Colaboratory]
1 | df_iris = pd.DataFrame(iris.data, columns = iris.feature_names) |
describe関数を実行すると、平均値・最小値・最大値などデータの全体像を確認することができます。
[実行結果]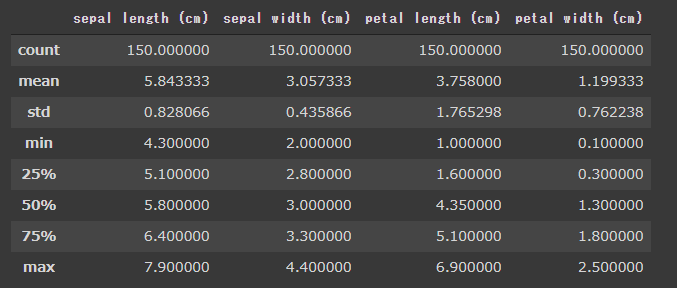
データ数は欠損値がなく全て150個で、平均としてはがく(Sepal)の長さが一番広く、花びら(Petal)の幅が一番せまいことなどが分かります。
データの可視化
pairplot関数を使って、各変数のペアごとに散布図を表示します。
[Google Colaboratory]
1 | import seaborn as sns |
[実行結果]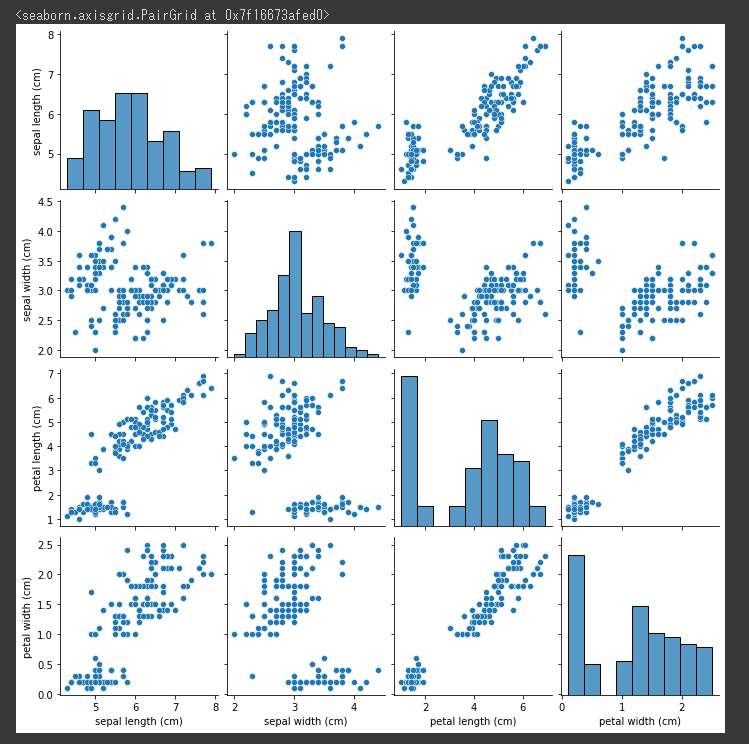
一番確認しやすい傾向としては、petal lengthとpetal widthの関係性が右肩上がりになっていることです。
次回は、今回読み込んだデータを参照しk-means法でクラスタリングを行います。