前回、広げたマップに対してゴールしたときの報酬を増やみましたが、ほとんどゴールにたどり着くことができませんでした。
[広くしたマップイメージ]
今回は単純に学習回数を増やして、攻略を目指します。
学習回数を増やす
これまでの改善で、(たまたまかもしれませんが)何回かはゴールすることもあるようなのでもう少し学習回数を増やせば攻略できるのではないか・・・と考えました。
そこで今回は単純に学習回数をこれまでの5倍に増やしてみます。
修正箇所は32行目となります。
[ソース]
1 | # 警告を非表示 |
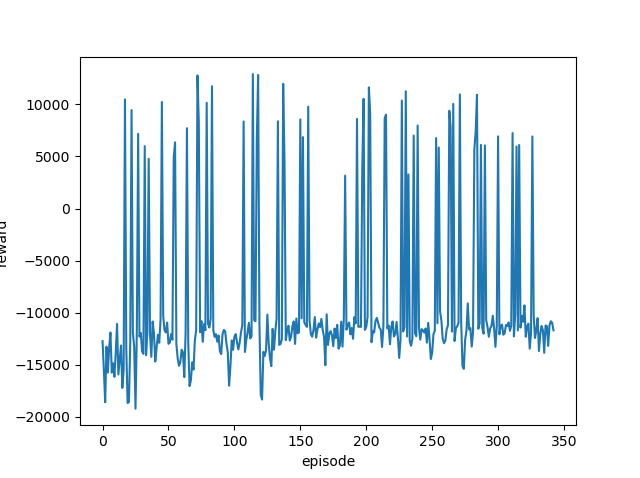
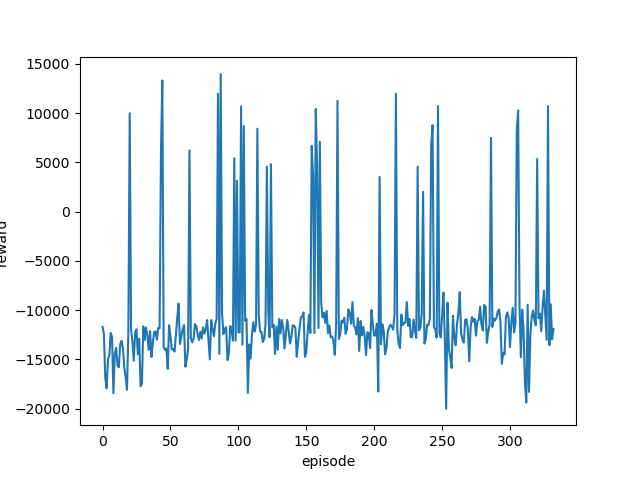
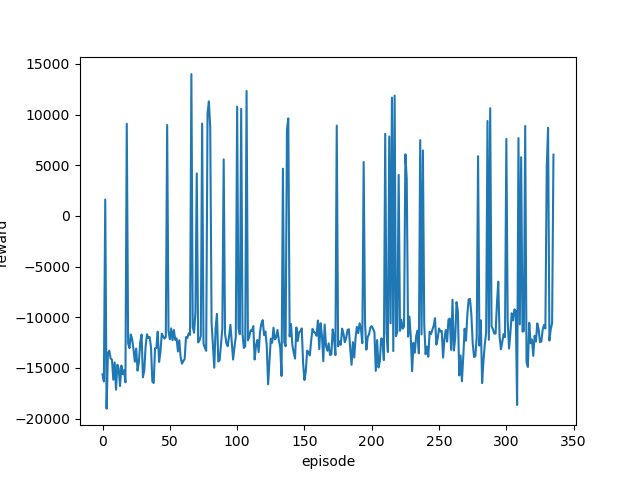
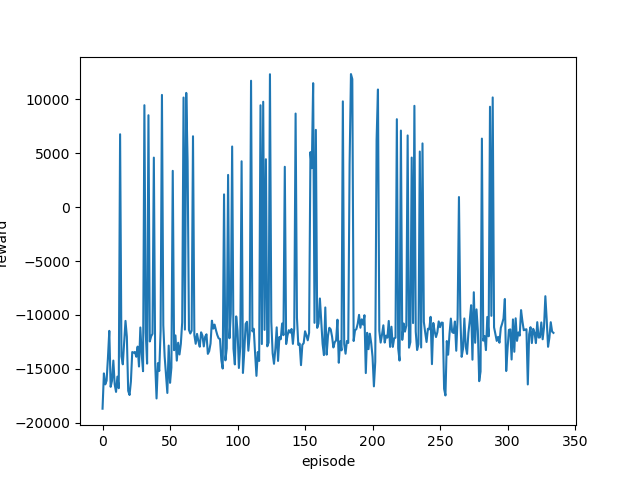
前回と同じように学習率を変更しながら実行し、それぞれの最終結果と平均報酬遷移(グラフ)を確認します。
[結果]
| 学習率 | 最終位置・最終報酬 | 平均報酬遷移 |
|---|---|---|
| 0.01 |  |
 |
| 0.05 |  |
 |
| 0.1 |  |
 |
| 0.5 |  |
 |
| 1.0 |  |
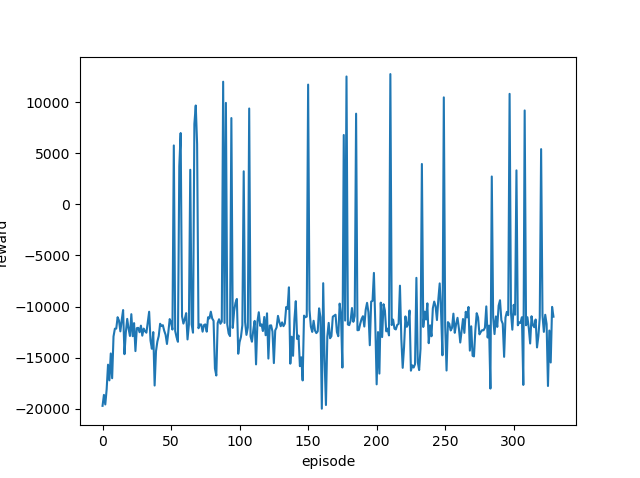 |
どの学習率でも同じような結果となりました。
ゴールまでたどり着く(最終報酬がプラスになる)ことは何度もあるのですが、その状態が続くことはありません。
つまりきちんと学習できていません。
行動報酬や学習回数を調整してきましたが、もしかしたら別の対策(切り口)が必要なのかもしれません。
次回は一旦これまでの改善点をまとめたいと思います。