前回記事で山超えのコースを学習・攻略しようとしましたが、うまく学習できませんでした。
[橋を渡るコースを山でふさいだマップイメージ]

今回は、学習率と報酬を調整してマップ攻略を目指します。
学習率と報酬の調整
学習率と報酬をいろいろと変更してみて、最終的には下記のように設定し攻略することができました。
- 学習率を1に設定(train6.py 25行目のlearning_rateオプションで設定)
- ゴール時の報酬を2000に変更(env6.py 92行目を修正)
[ソース]
1 | # 警告を非表示 |
実行結果(ログ)は以下のようになります。
[実行結果]
| explained_variance | 2.03e-06 |
| fps | 31 |
| nupdates | 1 |
| policy_entropy | 1.39 |
| policy_loss | -406 |
| total_timesteps | 20 |
| value_loss | 1.37e+05 |
| ep_len_mean | 201 |
| ep_reward_mean | -322 |
| explained_variance | 0 |
| fps | 948 |
| nupdates | 100 |
| policy_entropy | 0.0541 |
| policy_loss | -0.00449 |
| total_timesteps | 2000 |
| value_loss | 0.218 |
| ep_len_mean | 201 |
| ep_reward_mean | -258 |
| explained_variance | 0.00392 |
| fps | 1099 |
| nupdates | 200 |
| policy_entropy | 0.388 |
| policy_loss | -0.0641 |
| total_timesteps | 4000 |
| value_loss | 0.0191 |
| ep_len_mean | 201 |
| ep_reward_mean | -269 |
| explained_variance | -0.0365 |
| fps | 1158 |
| nupdates | 300 |
| policy_entropy | 1.35 |
| policy_loss | -0.052 |
| total_timesteps | 6000 |
| value_loss | 0.002 |
| ep_len_mean | 201 |
| ep_reward_mean | -409 |
| explained_variance | -4.18 |
| fps | 1188 |
| nupdates | 400 |
| policy_entropy | 1.35 |
| policy_loss | -0.00553 |
| total_timesteps | 8000 |
| value_loss | 5.43e-05 |
| ep_len_mean | 201 |
| ep_reward_mean | -466 |
| explained_variance | -0.000672 |
| fps | 1207 |
| nupdates | 500 |
| policy_entropy | 1.32 |
| policy_loss | -55.1 |
| total_timesteps | 10000 |
| value_loss | 3.66e+03 |
| ep_len_mean | 201 |
| ep_reward_mean | -498 |
| explained_variance | -3.39e+04 |
| fps | 1219 |
| nupdates | 600 |
| policy_entropy | 1.31 |
| policy_loss | -0.00111 |
| total_timesteps | 12000 |
| value_loss | 0.00047 |
| ep_len_mean | 201 |
| ep_reward_mean | -512 |
| explained_variance | -37 |
| fps | 1228 |
| nupdates | 700 |
| policy_entropy | 1.29 |
| policy_loss | -0.0169 |
| total_timesteps | 14000 |
| value_loss | 3.5e-05 |
| ep_len_mean | 201 |
| ep_reward_mean | -512 |
| explained_variance | -1.11e-05 |
| fps | 1235 |
| nupdates | 800 |
| policy_entropy | 1.28 |
| policy_loss | -57.6 |
| total_timesteps | 16000 |
| value_loss | 3.66e+03 |
| ep_len_mean | 201 |
| ep_reward_mean | -482 |
| explained_variance | -7 |
| fps | 1240 |
| nupdates | 900 |
| policy_entropy | 1.36 |
| policy_loss | -0.0157 |
| total_timesteps | 18000 |
| value_loss | 5.22e-06 |
| ep_len_mean | 201 |
| ep_reward_mean | -476 |
| explained_variance | -4.79 |
| fps | 1244 |
| nupdates | 1000 |
| policy_entropy | 1.32 |
| policy_loss | -0.0135 |
| total_timesteps | 20000 |
| value_loss | 1.72e-06 |
| ep_len_mean | 201 |
| ep_reward_mean | -490 |
| explained_variance | -461 |
| fps | 1246 |
| nupdates | 1100 |
| policy_entropy | 1.38 |
| policy_loss | -0.0131 |
| total_timesteps | 22000 |
| value_loss | 1.42e-06 |
| ep_len_mean | 201 |
| ep_reward_mean | -518 |
| explained_variance | -20.4 |
| fps | 1248 |
| nupdates | 1200 |
| policy_entropy | 1.38 |
| policy_loss | -0.0222 |
| total_timesteps | 24000 |
| value_loss | 6.51e-05 |
| ep_len_mean | 201 |
| ep_reward_mean | -531 |
| explained_variance | -22.4 |
| fps | 1250 |
| nupdates | 1300 |
| policy_entropy | 1.37 |
| policy_loss | -0.015 |
| total_timesteps | 26000 |
| value_loss | 2.2e-06 |
| ep_len_mean | 201 |
| ep_reward_mean | -480 |
| explained_variance | -0.00395 |
| fps | 1251 |
| nupdates | 1400 |
| policy_entropy | 1.34 |
| policy_loss | -79.9 |
| total_timesteps | 28000 |
| value_loss | 5.28e+03 |
| ep_len_mean | 201 |
| ep_reward_mean | -450 |
| explained_variance | -3.2 |
| fps | 1252 |
| nupdates | 1500 |
| policy_entropy | 1.3 |
| policy_loss | -0.0117 |
| total_timesteps | 30000 |
| value_loss | 3.33e-06 |
| ep_len_mean | 201 |
| ep_reward_mean | -426 |
| explained_variance | 0.413 |
| fps | 1253 |
| nupdates | 1600 |
| policy_entropy | 1.35 |
| policy_loss | -0.0134 |
| total_timesteps | 32000 |
| value_loss | 1.12e-06 |
| ep_len_mean | 201 |
| ep_reward_mean | -392 |
| explained_variance | -0.00011 |
| fps | 1254 |
| nupdates | 1700 |
| policy_entropy | 1.27 |
| policy_loss | -22 |
| total_timesteps | 34000 |
| value_loss | 970 |
| ep_len_mean | 201 |
| ep_reward_mean | -377 |
| explained_variance | 1.26e-05 |
| fps | 1255 |
| nupdates | 1800 |
| policy_entropy | 1.27 |
| policy_loss | -124 |
| total_timesteps | 36000 |
| value_loss | 7.82e+03 |
| ep_len_mean | 201 |
| ep_reward_mean | -377 |
| explained_variance | 0.000336 |
| fps | 1256 |
| nupdates | 1900 |
| policy_entropy | 1.32 |
| policy_loss | 59.4 |
| total_timesteps | 38000 |
| value_loss | 4.07e+03 |
| ep_len_mean | 201 |
| ep_reward_mean | -364 |
| explained_variance | 0.000371 |
| fps | 1257 |
| nupdates | 2000 |
| policy_entropy | 1.35 |
| policy_loss | 116 |
| total_timesteps | 40000 |
| value_loss | 7.81e+03 |
| ep_len_mean | 201 |
| ep_reward_mean | -359 |
| explained_variance | -1.94 |
| fps | 1257 |
| nupdates | 2100 |
| policy_entropy | 1.38 |
| policy_loss | -0.0157 |
| total_timesteps | 42000 |
| value_loss | 4.23e-06 |
| ep_len_mean | 201 |
| ep_reward_mean | -336 |
| explained_variance | 0.494 |
| fps | 1258 |
| nupdates | 2200 |
| policy_entropy | 1.38 |
| policy_loss | -0.0175 |
| total_timesteps | 44000 |
| value_loss | 8.93e-06 |
| ep_len_mean | 201 |
| ep_reward_mean | -313 |
| explained_variance | 0.071 |
| fps | 1259 |
| nupdates | 2300 |
| policy_entropy | 1.38 |
| policy_loss | -0.0205 |
| total_timesteps | 46000 |
| value_loss | 2.63e-05 |
| ep_len_mean | 201 |
| ep_reward_mean | -318 |
| explained_variance | -3.05 |
| fps | 1259 |
| nupdates | 2400 |
| policy_entropy | 1.38 |
| policy_loss | -0.0126 |
| total_timesteps | 48000 |
| value_loss | 1.01e-05 |
| ep_len_mean | 201 |
| ep_reward_mean | -308 |
| explained_variance | -0.223 |
| fps | 1260 |
| nupdates | 2500 |
| policy_entropy | 1.37 |
| policy_loss | -0.0161 |
| total_timesteps | 50000 |
| value_loss | 4.16e-06 |
| ep_len_mean | 201 |
| ep_reward_mean | -304 |
| explained_variance | -0.795 |
| fps | 1260 |
| nupdates | 2600 |
| policy_entropy | 1.37 |
| policy_loss | -0.0182 |
| total_timesteps | 52000 |
| value_loss | 1.62e-05 |
| ep_len_mean | 201 |
| ep_reward_mean | -300 |
| explained_variance | -0.311 |
| fps | 1261 |
| nupdates | 2700 |
| policy_entropy | 1.38 |
| policy_loss | -0.0186 |
| total_timesteps | 54000 |
| value_loss | 1.6e-05 |
| ep_len_mean | 199 |
| ep_reward_mean | -264 |
| explained_variance | 0.0573 |
| fps | 1261 |
| nupdates | 2800 |
| policy_entropy | 1.38 |
| policy_loss | -0.0212 |
| total_timesteps | 56000 |
| value_loss | 3.45e-05 |
| ep_len_mean | 199 |
| ep_reward_mean | -226 |
| explained_variance | -3.36 |
| fps | 1262 |
| nupdates | 2900 |
| policy_entropy | 1.36 |
| policy_loss | -0.0107 |
| total_timesteps | 58000 |
| value_loss | 1.11e-05 |
| ep_len_mean | 199 |
| ep_reward_mean | -221 |
| explained_variance | -0.187 |
| fps | 1262 |
| nupdates | 3000 |
| policy_entropy | 1.38 |
| policy_loss | -0.0219 |
| total_timesteps | 60000 |
| value_loss | 4.85e-05 |
| ep_len_mean | 199 |
| ep_reward_mean | -215 |
| explained_variance | -5.68 |
| fps | 1262 |
| nupdates | 3100 |
| policy_entropy | 1.36 |
| policy_loss | -0.0262 |
| total_timesteps | 62000 |
| value_loss | 0.000103 |
| ep_len_mean | 198 |
| ep_reward_mean | -170 |
| explained_variance | 0.000507 |
| fps | 1263 |
| nupdates | 3200 |
| policy_entropy | 1.38 |
| policy_loss | 119 |
| total_timesteps | 64000 |
| value_loss | 7.81e+03 |
| ep_len_mean | 198 |
| ep_reward_mean | -175 |
| explained_variance | -0.506 |
| fps | 1263 |
| nupdates | 3300 |
| policy_entropy | 1.38 |
| policy_loss | -0.0174 |
| total_timesteps | 66000 |
| value_loss | 1.03e-05 |
| ep_len_mean | 197 |
| ep_reward_mean | -145 |
| explained_variance | 3.67e-05 |
| fps | 1263 |
| nupdates | 3400 |
| policy_entropy | 1.38 |
| policy_loss | 20.5 |
| total_timesteps | 68000 |
| value_loss | 1.44e+03 |
| ep_len_mean | 196 |
| ep_reward_mean | -114 |
| explained_variance | -1.71 |
| fps | 1263 |
| nupdates | 3500 |
| policy_entropy | 1.37 |
| policy_loss | -0.0166 |
| total_timesteps | 70000 |
| value_loss | 1.17e-05 |
| ep_len_mean | 196 |
| ep_reward_mean | -66.8 |
| explained_variance | -1.37 |
| fps | 1263 |
| nupdates | 3600 |
| policy_entropy | 1.38 |
| policy_loss | -0.0194 |
| total_timesteps | 72000 |
| value_loss | 2.63e-05 |
| ep_len_mean | 195 |
| ep_reward_mean | -11.9 |
| explained_variance | -3.93 |
| fps | 1264 |
| nupdates | 3700 |
| policy_entropy | 1.37 |
| policy_loss | -0.0467 |
| total_timesteps | 74000 |
| value_loss | 0.000802 |
| ep_len_mean | 196 |
| ep_reward_mean | 5.91 |
| explained_variance | -1.15 |
| fps | 1264 |
| nupdates | 3800 |
| policy_entropy | 1.38 |
| policy_loss | -0.0054 |
| total_timesteps | 76000 |
| value_loss | 6.35e-05 |
| ep_len_mean | 193 |
| ep_reward_mean | 73 |
| explained_variance | -1.33 |
| fps | 1264 |
| nupdates | 3900 |
| policy_entropy | 1.36 |
| policy_loss | -0.0216 |
| total_timesteps | 78000 |
| value_loss | 5.23e-05 |
| ep_len_mean | 189 |
| ep_reward_mean | 255 |
| explained_variance | -2.78 |
| fps | 1264 |
| nupdates | 4000 |
| policy_entropy | 1.29 |
| policy_loss | -0.0768 |
| total_timesteps | 80000 |
| value_loss | 0.00266 |
| ep_len_mean | 189 |
| ep_reward_mean | 278 |
| explained_variance | 0.157 |
| fps | 1264 |
| nupdates | 4100 |
| policy_entropy | 1.37 |
| policy_loss | -0.0131 |
| total_timesteps | 82000 |
| value_loss | 1.75e-05 |
| ep_len_mean | 170 |
| ep_reward_mean | 707 |
| explained_variance | 0.000953 |
| fps | 1264 |
| nupdates | 4200 |
| policy_entropy | 0.94 |
| policy_loss | 1.01e+03 |
| total_timesteps | 84000 |
| value_loss | 2.01e+06 |
| ep_len_mean | 137 |
| ep_reward_mean | 1.21e+03 |
| explained_variance | 0.471 |
| fps | 1263 |
| nupdates | 4300 |
| policy_entropy | 0.83 |
| policy_loss | -0.0847 |
| total_timesteps | 86000 |
| value_loss | 0.114 |
| ep_len_mean | 68.7 |
| ep_reward_mean | 1.86e+03 |
| explained_variance | 0.00681 |
| fps | 1263 |
| nupdates | 4400 |
| policy_entropy | 0.517 |
| policy_loss | 74.5 |
| total_timesteps | 88000 |
| value_loss | 1.03e+06 |
| ep_len_mean | 23.5 |
| ep_reward_mean | 1.97e+03 |
| explained_variance | 0.00852 |
| fps | 1262 |
| nupdates | 4500 |
| policy_entropy | 0.211 |
| policy_loss | 59.4 |
| total_timesteps | 90000 |
| value_loss | 3.15e+06 |
| ep_len_mean | 21.2 |
| ep_reward_mean | 1.98e+03 |
| explained_variance | 0.0106 |
| fps | 1261 |
| nupdates | 4600 |
| policy_entropy | 0.149 |
| policy_loss | 20.5 |
| total_timesteps | 92000 |
| value_loss | 2.26e+06 |
| ep_len_mean | 22.6 |
| ep_reward_mean | 1.96e+03 |
| explained_variance | 0.0142 |
| fps | 1260 |
| nupdates | 4700 |
| policy_entropy | 0.141 |
| policy_loss | 399 |
| total_timesteps | 94000 |
| value_loss | 2.72e+06 |
| ep_len_mean | 20.8 |
| ep_reward_mean | 1.98e+03 |
| explained_variance | 0.011 |
| fps | 1260 |
| nupdates | 4800 |
| policy_entropy | 0.104 |
| policy_loss | 7.25 |
| total_timesteps | 96000 |
| value_loss | 1.78e+06 |
| ep_len_mean | 20.4 |
| ep_reward_mean | 1.98e+03 |
| explained_variance | 0.0091 |
| fps | 1260 |
| nupdates | 4900 |
| policy_entropy | 0.0783 |
| policy_loss | 5.12 |
| total_timesteps | 98000 |
| value_loss | 1.99e+06 |
| ep_len_mean | 20.4 |
| ep_reward_mean | 1.98e+03 |
| explained_variance | 0.00713 |
| fps | 1260 |
| nupdates | 5000 |
| policy_entropy | 0.115 |
| policy_loss | -0.78 |
| total_timesteps | 100000 |
| value_loss | 1.28e+06 |
| ep_len_mean | 20.4 |
| ep_reward_mean | 1.98e+03 |
| explained_variance | 0.0218 |
| fps | 1259 |
| nupdates | 5100 |
| policy_entropy | 0.0424 |
| policy_loss | 0.498 |
| total_timesteps | 102000 |
| value_loss | 1.57e+06 |
| ep_len_mean | 20.1 |
| ep_reward_mean | 1.98e+03 |
| explained_variance | 0.00849 |
| fps | 1259 |
| nupdates | 5200 |
| policy_entropy | 0.0179 |
| policy_loss | -0.0378 |
| total_timesteps | 104000 |
| value_loss | 1.72e+05 |
| ep_len_mean | 20.1 |
| ep_reward_mean | 1.98e+03 |
| explained_variance | 0.0211 |
| fps | 1259 |
| nupdates | 5300 |
| policy_entropy | 0.024 |
| policy_loss | 0.205 |
| total_timesteps | 106000 |
| value_loss | 1.26e+06 |
| ep_len_mean | 20.1 |
| ep_reward_mean | 1.98e+03 |
| explained_variance | 0.039 |
| fps | 1259 |
| nupdates | 5400 |
| policy_entropy | 0.0104 |
| policy_loss | 0.972 |
| total_timesteps | 108000 |
| value_loss | 2.55e+06 |
| ep_len_mean | 20 |
| ep_reward_mean | 1.98e+03 |
| explained_variance | 0.0334 |
| fps | 1259 |
| nupdates | 5500 |
| policy_entropy | 0.00561 |
| policy_loss | 0.349 |
| total_timesteps | 110000 |
| value_loss | 2.52e+06 |
| ep_len_mean | 20 |
| ep_reward_mean | 1.98e+03 |
| explained_variance | 0.0375 |
| fps | 1259 |
| nupdates | 5600 |
| policy_entropy | 0.0026 |
| policy_loss | 0.306 |
| total_timesteps | 112000 |
| value_loss | 2.62e+06 |
| ep_len_mean | 20 |
| ep_reward_mean | 1.98e+03 |
| explained_variance | 0.0361 |
| fps | 1258 |
| nupdates | 5700 |
| policy_entropy | 0.00159 |
| policy_loss | 0.145 |
| total_timesteps | 114000 |
| value_loss | 2.61e+06 |
| ep_len_mean | 20 |
| ep_reward_mean | 1.98e+03 |
| explained_variance | 0.0308 |
| fps | 1258 |
| nupdates | 5800 |
| policy_entropy | 0.00105 |
| policy_loss | 0.089 |
| total_timesteps | 116000 |
| value_loss | 2.6e+06 |
| ep_len_mean | 20 |
| ep_reward_mean | 1.98e+03 |
| explained_variance | 0.0279 |
| fps | 1258 |
| nupdates | 5900 |
| policy_entropy | 0.000787 |
| policy_loss | 0.0623 |
| total_timesteps | 118000 |
| value_loss | 2.59e+06 |
| ep_len_mean | 21.8 |
| ep_reward_mean | 1.96e+03 |
| explained_variance | -0.983 |
| fps | 1258 |
| nupdates | 6000 |
| policy_entropy | 0.135 |
| policy_loss | -8.94 |
| total_timesteps | 120000 |
| value_loss | 919 |
| ep_len_mean | 36.1 |
| ep_reward_mean | 1.8e+03 |
| explained_variance | 0.0285 |
| fps | 1258 |
| nupdates | 6100 |
| policy_entropy | 0.202 |
| policy_loss | 2.62 |
| total_timesteps | 122000 |
| value_loss | 8.08e+05 |
| ep_len_mean | 21.1 |
| ep_reward_mean | 1.98e+03 |
| explained_variance | 0.0263 |
| fps | 1258 |
| nupdates | 6200 |
| policy_entropy | 0.0413 |
| policy_loss | 0.446 |
| total_timesteps | 124000 |
| value_loss | 9.49e+05 |
| ep_len_mean | 20.3 |
| ep_reward_mean | 1.98e+03 |
| explained_variance | 0.0725 |
| fps | 1257 |
| nupdates | 6300 |
| policy_entropy | 0.0795 |
| policy_loss | 1.3 |
| total_timesteps | 126000 |
| value_loss | 2.49e+06 |
| ep_len_mean | 20.6 |
| ep_reward_mean | 1.98e+03 |
| explained_variance | 0.0398 |
| fps | 1256 |
| nupdates | 6400 |
| policy_entropy | 0.0273 |
| policy_loss | 1.16 |
| total_timesteps | 128000 |
| value_loss | 2.37e+06 |
☆山山山 山
川川山山 G
山 三三 山 山
山 川川山
山 山山
山 山 山 山
山
山 山山 山
reward: [-1.] total_reward [-1.]
S山山山 山
☆ 川川山山 G
山 三三 山 山
山 川川山
山 山山
山 山 山 山
山
山 山山 山
reward: [-1.] total_reward [-2.]
☆山山山 山
川川山山 G
山 三三 山 山
山 川川山
山 山山
山 山 山 山
山
山 山山 山
reward: [-1.] total_reward [-3.]
S山山山 山
☆ 川川山山 G
山 三三 山 山
山 川川山
山 山山
山 山 山 山
山
山 山山 山
reward: [-1.] total_reward [-4.]
S山山山 山
☆川川山山 G
山 三三 山 山
山 川川山
山 山山
山 山 山 山
山
山 山山 山
reward: [-1.] total_reward [-5.]
S山山山 山
川川山山 G
山☆三三 山 山
山 川川山
山 山山
山 山 山 山
山
山 山山 山
reward: [-1.] total_reward [-6.]
S山山山 山
川川山山 G
山 三三 山 山
山☆川川山
山 山山
山 山 山 山
山
山 山山 山
reward: [-1.] total_reward [-7.]
S山山山 山
川川山山 G
山 三三 山 山
山 川川山
☆山 山山
山 山 山 山
山
山 山山 山
reward: [-1.] total_reward [-8.]
S山山山 山
川川山山 G
山 三三 山 山
山 川川山
山 山山
山☆山 山 山
山
山 山山 山
reward: [-1.] total_reward [-9.]
S山山山 山
川川山山 G
山 三三 山 山
山 川川山
山 山山
山 山 山 山
山☆
山 山山 山
reward: [-1.] total_reward [-10.]
S山山山 山
川川山山 G
山 三三 山 山
山 川川山
山 山山
山 山 山 山
山 ☆
山 山山 山
reward: [-1.] total_reward [-11.]
S山山山 山
川川山山 G
山 三三 山 山
山 川川山
山 山山
山 山 山 山
山 ☆
山 山山 山
reward: [-1.] total_reward [-12.]
S山山山 山
川川山山 G
山 三三 山 山
山 川川山
山 山山
山 山 山 山
山 ☆
山 山山 山
reward: [-1.] total_reward [-13.]
S山山山 山
川川山山 G
山 三三 山 山
山 川川山
山 山山
山 山 山 山
山 ☆
山 山山 山
reward: [-1.] total_reward [-14.]
S山山山 山
川川山山 G
山 三三 山 山
山 川川山
山 山山
山 山 山 山
山 ☆
山 山山 山
reward: [-1.] total_reward [-15.]
S山山山 山
川川山山 G
山 三三 山 山
山 川川山
山 山山
山 山 山 山
山 ☆
山 山山 山
reward: [-1.] total_reward [-16.]
S山山山 山
川川山山 G
山 三三 山 山
山 川川山
山 山山
山 山 山 山☆
山
山 山山 山
reward: [-1.] total_reward [-17.]
S山山山 山
川川山山 G
山 三三 山 山
山 川川山
山 山山☆
山 山 山 山
山
山 山山 山
reward: [-1.] total_reward [-18.]
S山山山 山
川川山山 G
山 三三 山 山
山 川川山 ☆
山 山山
山 山 山 山
山
山 山山 山
reward: [-1.] total_reward [-19.]
S山山山 山
川川山山 G
山 三三 山 山
山 川川山 ☆
山 山山
山 山 山 山
山
山 山山 山
reward: [-1.] total_reward [-20.]
S山山山 山
川川山山 G
山 三三 山☆山
山 川川山
山 山山
山 山 山 山
山
山 山山 山
reward: [-1.] total_reward [-21.]
S山山山 山
川川山山☆G
山 三三 山 山
山 川川山
山 山山
山 山 山 山
山
山 山山 山
reward: [2000.] total_reward [1979.]
total_reward: [1979.]
スタート時に一度出戻りしますが、その後はまっすぐゴールに向かっています。
平均報酬をグラフ化
確認のために学習中の平均報酬推移をグラフにします。
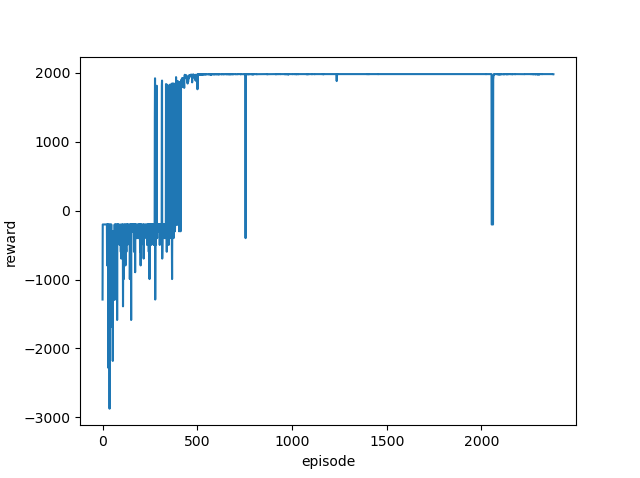
400エピソードを超えたあたりからゴール報酬の2000を取得できるようになっていることが分かります。
調整内容のまとめ
報酬に関しては、ゴールまでの距離が遠くなるほど大きめの報酬にしないといけないと感じました。
ゴールの報酬が、ゴール地点から波紋のように広がっていくイメージです。
また学習率はエージェントの大胆さを調整しているイメージでした。
学習率が低い場合は、臆病な感じで近くに障害(今回の場合は川)があるとそこに近づこうとはせずにスタート位置付近から移動しようとしません。
逆に学習率を高く設定した場合は、大胆にいろいろ行動するようになり、(川に飛び込んでしまうこともありますが)最終的にゴールにたどり着くことができるようになりました。
カスタムGym環境に合わせ報酬も学習率も適切に設定する必要性を強く感じました。