Natural Language Processing with Disaster Tweetsrに関する6回目の記事です。
今回はBaselineモデルを使って予測を行い、最後にKaggleに結果を提出します。
Baselineモデルの準備
Baselineモデルを作成します。
最適化アルゴリズムとしてはAdamを使います。
Adamは、移動平均で振動を抑制するモーメンタム と 学習率を調整して振動を抑制するRMSProp を組み合わせています。
また、embedding_matrixは単語ごとにベクター値を設定したものです。(前回記事をご参照ください)
[ソース]
1 | model = Sequential() |
[結果]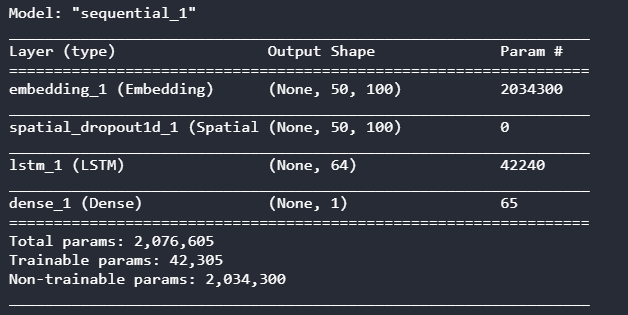
データ分割
ツイートデータを配列化したものを(tweet_pad)、訓練用のデータ(正解ラベルとそれ以外)と検証用のデータ(正解ラベルとそれ以外)に分割します。
[ソース]
1 | train=tweet_pad[:tweet.shape[0]] |
[結果]
学習
分割したデータを使って学習を行います。(少々時間がかかります。)
[ソース]
1 | history=model.fit(X_train,y_train,batch_size=4,epochs=15,validation_data=(X_test,y_test),verbose=2) |
[結果]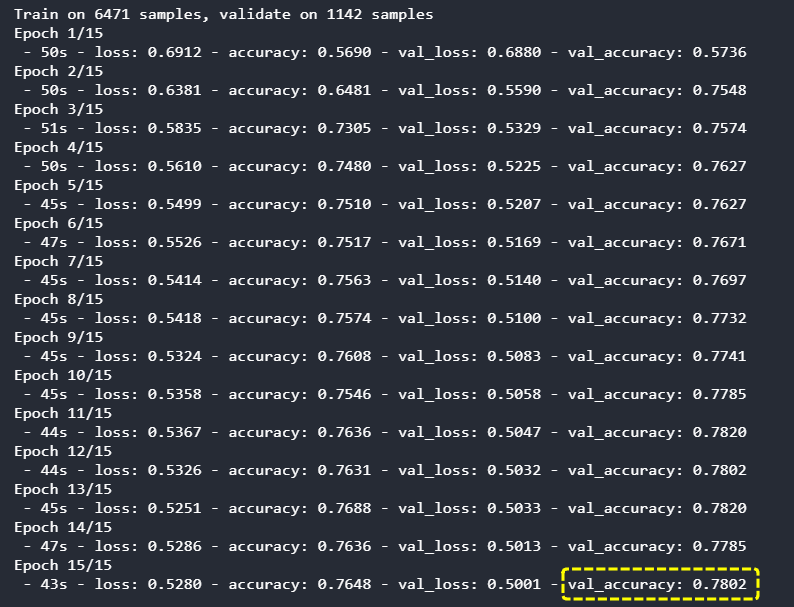
最終的な正解率(検証用)は78.02%となりました。
提出用ファイルの作成
提出用のCSVファイルを作成します。
提出のサンプルファイル(sample_submission.cs)を一旦読み込んで、targetに予測した結果(災害ツイートかどうか)を上書いています。
[ソース]
1 | sample_sub=pd.read_csv('../input/nlp-getting-started/sample_submission.csv') |
[結果]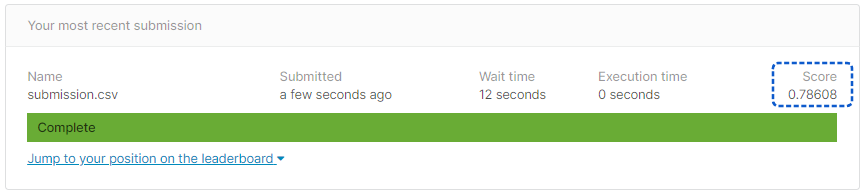
正解率は78.60%となりました。
それなりの結果かと思いますが、やはりいつもの8割の壁というものを感じてしまいます。