Random Forestというアルゴリズムを使って、タイタニックの生存率を予測します。
Random Forestはアンサンブル学習と呼ばれる学習の1つです。
アンサンブル学習は、いくつかの性能の低い分類器(弱仮説器)を組み合わせて、性能の高い1つの分類器を作る手法です。
データの読み込み
Kaggleに準備されているタイタニックの訓練データを読み込みます。
データの前処理(不要列の削除・欠損処理・カテゴリ変数の変換)と、正解ラベルとそれ以外にデータを分けるところまで一気に実行します。
[ソース]
1 | import pandas as pd |
Random Forestで予測
Random Forestのインスタンスを作成し、とても便利なcross_val_score関数で分割交差検証を行い、どのくらいの正答率になるか調べてみます。
[ソース]
1 | from sklearn import ensemble, model_selection |
[出力]
81.14%という、まずまずの正解率となりました。
Kaggleに提出
訓練データ全体で学習を行います。
その後、検証データを読み込み、推論・提出用のCSVの出力を行い、Kaggleに提出します。
[ソース]
1 | # 学習 |
[提出結果]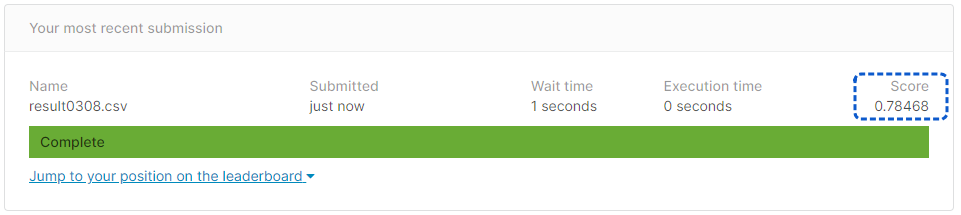
正解率78.46%となりました。
なかなか80%の壁を超えることができません・・・。