大量の生データそのままですと特徴がつかみにくいですが、平均値・中央値・標準偏差という統計量をみることでデータの特徴が捉えやすくなります。
タイタニックのデータで言えば、乗船客の年齢では何歳くらいの人が多いのか、男性と女性で年齢層は違うのか、料金層で人数がどのように分布しているのか、ということを調べることで乗客の特徴を把握しやすくなります。
pandasではdescribe関数で統計量を出力できますが、データの種別(量的データ・カテゴリデータ・日付データ)によって表現できるものが異なります。
量的データの統計量表示
まずはタイタニックデータを読み込みます。
1 | import pandas as pd |

量的データの統計量を表示します。
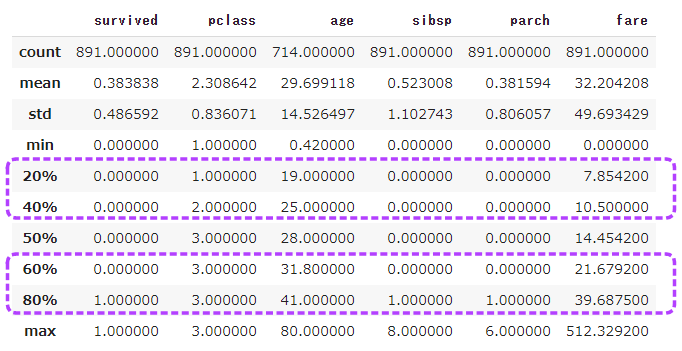
量的データの統計量としては下記の項目が表示されます。
| 統計量 | 内容 |
|---|---|
| count | データの個数。欠損値はカウントされません。 |
| mean | 平均値 |
| std | 標準偏差 |
| min,max | 最小値、最大値 |
| パーセンタイル | デフォルトで25%、50%、75%の位置を出力。50%が中央値。 |
1 | # 量的(数値)データの統計量を表示 |
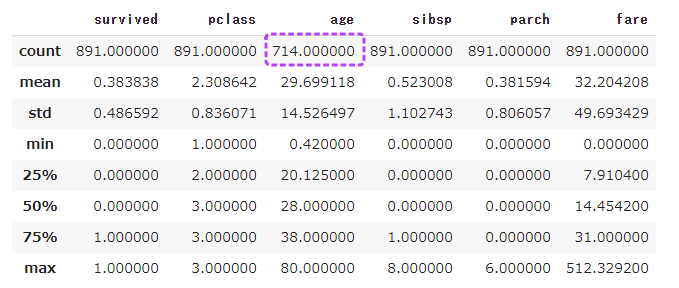
count行のageカラムを見ると、他のデータよりも数が少ないため、欠損値があることが分かります。
カテゴリーデータの統計量表示
カテゴリーデータの統計量を表示します。
カテゴリーデータの統計量を表示する場合は、describe関数にexclude=’number’を指定します。
カテゴリーデータの統計量としては下記の項目が表示されます。
| 統計量 | 内容 |
|---|---|
| count | データの個数。欠損値はカウントされません。 |
| unique | 一意な要素の個数 |
| top | 最頻値 |
| freq | 最頻値の頻度 |
1 | # カテゴリデータの統計量を表示 |
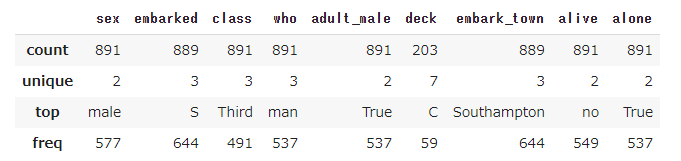
日付データの統計量表示
日付データの統計量を表示します。
日付データの統計量としては下記の項目が表示されます。
| 統計量 | 内容 |
|---|---|
| count | データの個数。欠損値はカウントされません。 |
| unique | 一意な要素の個数 |
| top | 最頻値 |
| freq | 最頻値の頻度 |
| first | 最初の日 |
| last | 最後の日 |
1 | # 日付データの統計量を表示 |

出力内容の変更
describe関数の返値はDataFrame形式なので、必要に応じて行や列を選択して出力することができます。
列count・meanを選択して表示します。
1 | # count,meanのみ出力 |

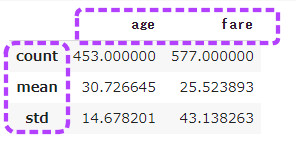
次に性別はmaleで、列がcount・mean、行がage・fareのデータを表示します。
1 | titanic[titanic.sex=='male'].describe().loc[['count', 'mean', 'std'],['age', 'fare']] |
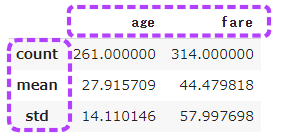
性別はfemaleで、列がcount・mean、行がage・fareのデータを表示します。
1 | titanic[titanic.sex=='female'].describe().loc[['count', 'mean', 'std'],['age', 'fare']] |
パーセンタイルの20%、40%、60%、80%を表示します。
1 | titanic.describe(percentiles=[0.2, 0.4, 0.6, 0.8]) |
データの特徴や新たな仮説を得るためには、どんな切り口で分析を行うかといった視点がとても大切です。
知識や経験がものをいう分野でありますが、自分なりに統計量を表示してみて関連性を確認することが重要だと感じました。
(実行環境としてGoogleさんのColaboratoryを使用ています。)
次回は、スライシングを行います。