前回行った10回投資シミュレーションの結果が意外と面白かったので、今回は少しだけ条件を変えてまた10回投資シミュレーションを行ってみます。
ビットコインデータを使っての10回投資シミュレーション
今回は、投資アルゴリズムと学習データ、検証データを変えずに、参照するデータ数 を 50 から 20 に変更してみます。
- 学習アルゴリズム
PPO2 - 参照する直前データ数
50→20 - 学習データ
[2020-06-29 16:00 ~ 2020-07-24 17:00] 1時間足データ - 検証データ
[2020-07-24 18:00 ~ 2020-07-12 03:00] 1時間足データ
10投資シミュレーションを10回行うソースコードは次のようになります。
1 | import os, gym |
26行目 と 50行目 で参照する直前データ数を50から20に変更しています。
10回投資シミュレーションを実行
上記コードを実行すると次のような結果になりました。
[コンソール出力]
1 | info: {'total_reward': 13300000.0, 'total_profit': 0.9904737506764453, 'position': 1} |
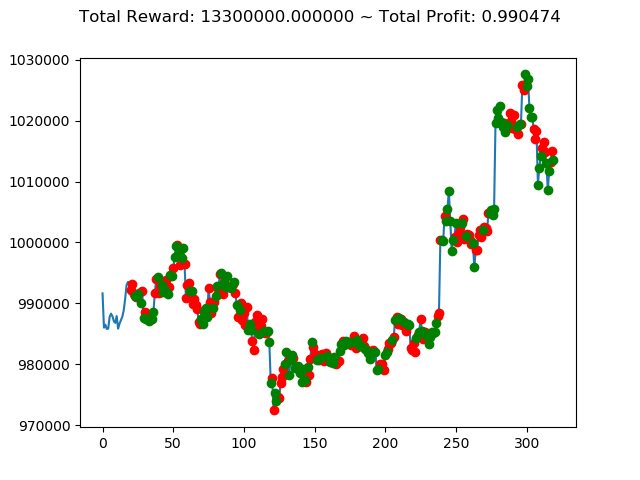
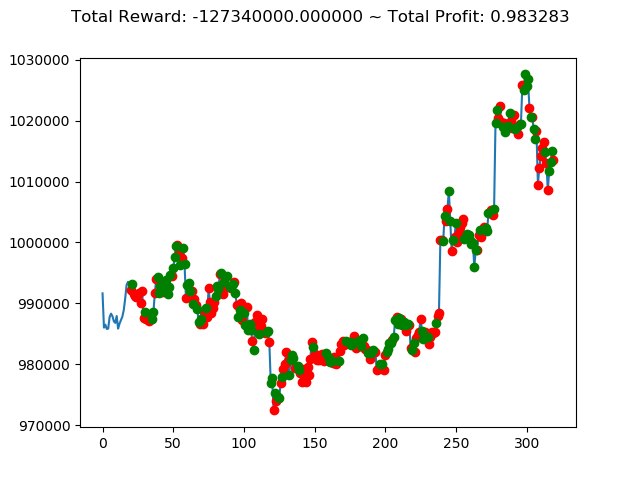
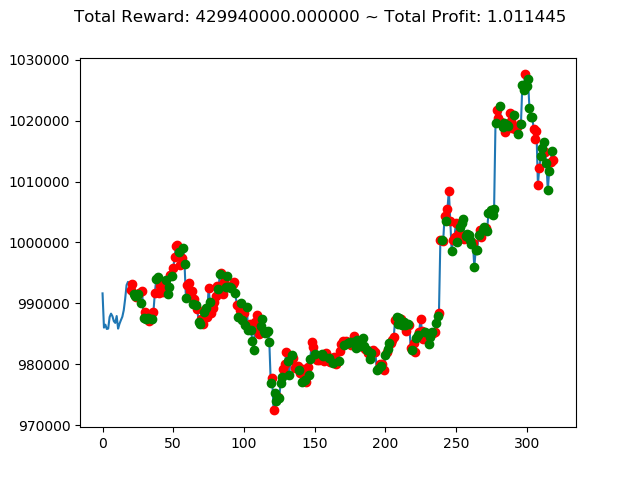
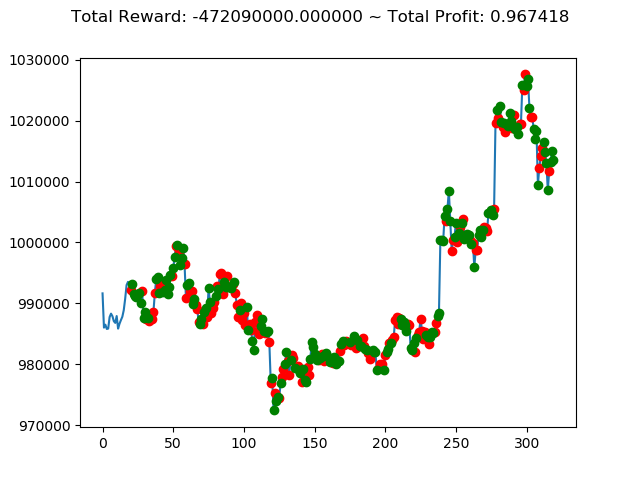
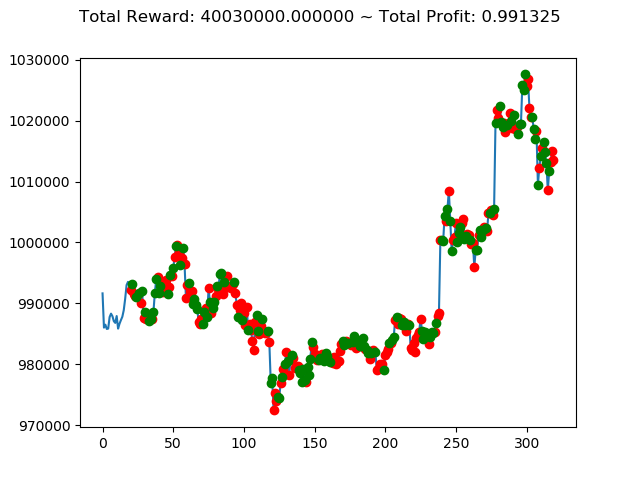
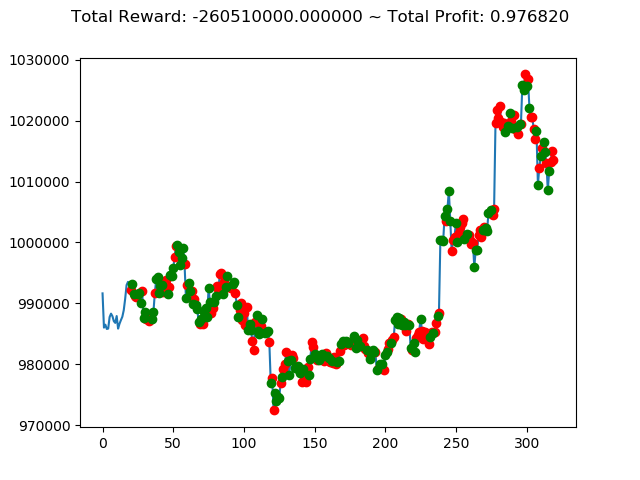
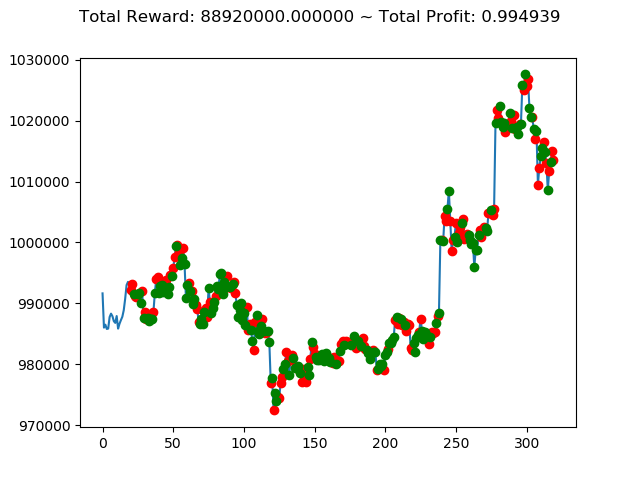
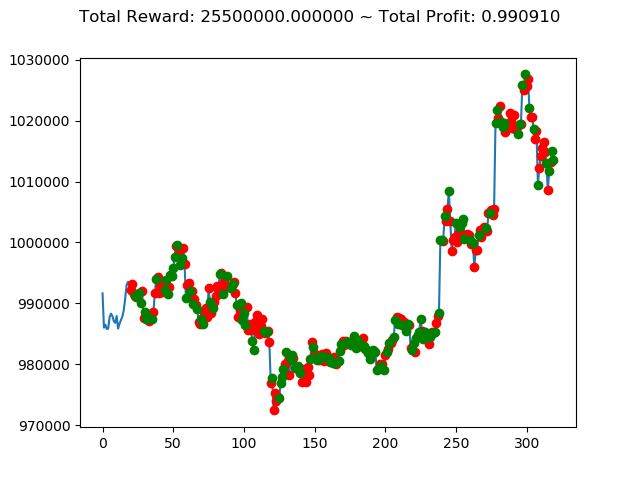
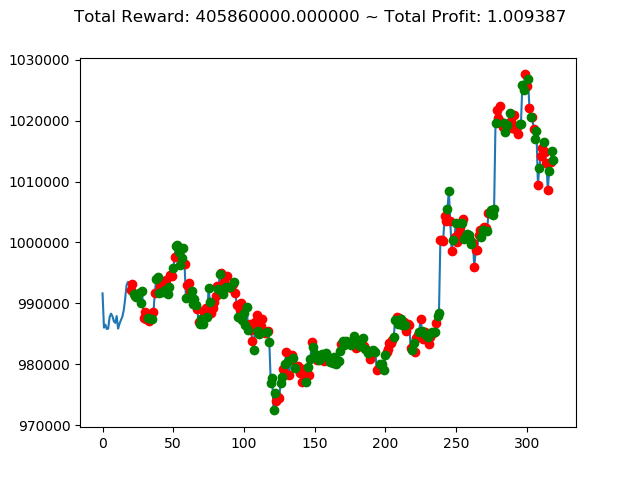
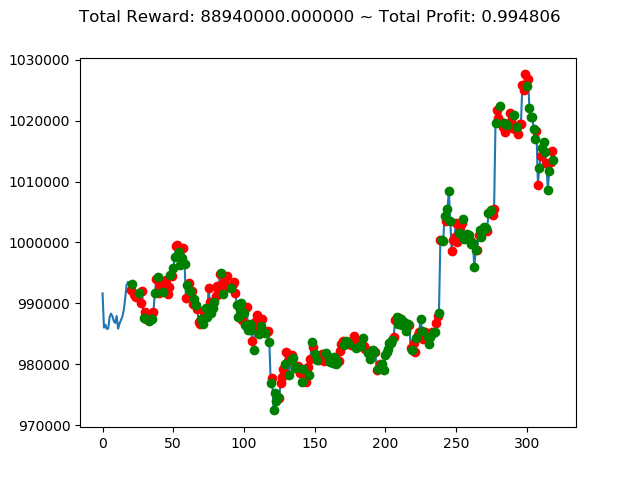
10回の投資結果としては7勝3敗となりました。
一番トータル収益の高い学習済みモデルを使えば4億円得られるというのは夢がありますねー。
ただ負けるときは2.6億円失ってしまうのはなかなかにオソロシイデス。