ランダム行動では報酬を見つけにくい環境に対応するために模倣学習を試してみます。
Atari環境の1つであるボーリングゲーム(Bowling)を実行環境とします。
(Windowsではうまく動作しなかったので、Ubuntu 19.10で動作確認しています。)
インストール
下記のコマンドを実行し、実行環境をインストールします。
1 | pip3 install gym |
人間のデモ収集
人間のデモ収集を行うコードは下記になります。
[コード]
1 | import random |
デモ収集にはgenerate_expert_trajを使います。引数の意味は下記の通りです。
- model(モデルまたはコールバック型)
モデルまたはコールバック - save_path(str型)
保存先のデモファイルのパス(拡張子なし) - env(gym.Env型)
環境 - n_timesteps(int型)
モデルの学習ステップ数 - n_episodes(int型)
記録するエピソード数 - image_folder(str型)
画像を使用する場合の保存フォルダ
返値はデモ demo(dict型)となります。
実行
実行すると、次のような画面が表示されます。右側のウィンドウにフォーカスをあてるとゲームを操作することができます。
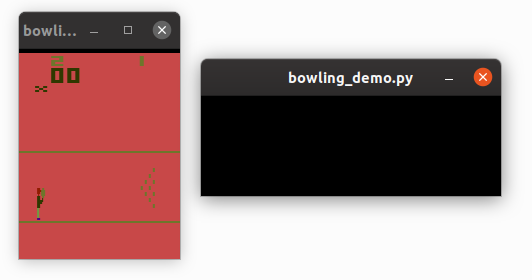
up、downで位置を選択し、fireでボールを投げます。
ボールを投げた後にup、downでボールの起動を曲げることができます。
10ゲーム(1エピソード)の人間の操作が収集され、bowling_demo.npzファイルとrecorded_imagesフォルダが出力されます。
- bowling_demo.npzファイル
Pythonの辞書形式で保存されます。
キーとしてactions、episode_returns、rewards、obs、episode_startsがあり、obsには画像への相対パスが格納されます。 - recorded_imagesフォルダ
各状態の画像が保存されます。
次回は、今回収集した人間のデモデータを使って事前学習を行います。