経験の蓄積と活用のトレードオフのバランスをとる手法としてEpsilon-Greedy法を実装します。
何枚かのコインから1枚を選んで、投げた時表が出れば報酬が得られるゲームを考えます。
各コインの表が出る確率はバラバラです。
必要なパッケージをインポートします。
1
2
| import random
import numpy as np
|
コイントスゲームの実装を行います。
head_probsは配列のパラメータで各コインの表が出る確率を指定します。
max_episode_stepsはコイントスを行う回数で、この回数の実行して表がでた回数が報酬となります。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
| class CoinToss():
def __init__(self, head_probs, max_episode_steps=30):
self.head_probs = head_probs
self.max_episode_steps = max_episode_steps
self.toss_count = 0
def __len__(self):
return len(self.head_probs)
def reset(self):
self.toss_count = 0
def step(self, action):
final = self.max_episode_steps - 1
if self.toss_count > final:
raise Exception("The step count exceeded maximum. Please reset env.")
else:
done = True if self.toss_count == final else False
if action >= len(self.head_probs):
raise Exception("The No.{} coin doesn't exist.".format(action))
else:
head_prob = self.head_probs[action]
if random.random() < head_prob:
reward = 1.0
else:
reward = 0.0
self.toss_count += 1
return reward, done
|
エージェントを作成します。
policy関数で、epsilonの確率でランダムにコインを選択し(探索)、それ以外の確率で各コインの期待値にそってコインを選択します(活用)。
play関数は、コイントスを行う処理です。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| class EpsilonGreedyAgent():
def __init__(self, epsilon):
self.epsilon = epsilon
self.V = []
def policy(self):
coins = range(len(self.V))
if random.random() < self.epsilon:
return random.choice(coins)
else:
return np.argmax(self.V)
def play(self, env):
N = [0] * len(env)
self.V = [0] * len(env)
env.reset()
done = False
rewards = []
while not done:
selected_coin = self.policy()
reward, done = env.step(selected_coin)
rewards.append(reward)
n = N[selected_coin]
coin_average = self.V[selected_coin]
new_average = (coin_average * n + reward) / (n + 1)
N[selected_coin] += 1
self.V[selected_coin] = new_average
return rewards
|
5枚のコインを用意し、コイントスの回数を変えながら、各エピソードにおける1回のコイントスあたりの報酬を記録していきます。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| if __name__ == "__main__":
import pandas as pd
import matplotlib.pyplot as plt
def main():
env = CoinToss([0.1, 0.5, 0.1, 0.9, 0.1])
epsilons = [0.0, 0.1, 0.2, 0.5, 0.8]
game_steps = list(range(10, 310, 10))
result = {}
for e in epsilons:
agent = EpsilonGreedyAgent(epsilon=e)
means = []
for s in game_steps:
env.max_episode_steps = s
rewards = agent.play(env)
means.append(np.mean(rewards))
result["epsilon={}".format(e)] = means
result["coin toss count"] = game_steps
result = pd.DataFrame(result)
result.set_index("coin toss count", drop=True, inplace=True)
result.plot.line(figsize=(10, 5))
plt.show()
main()
|
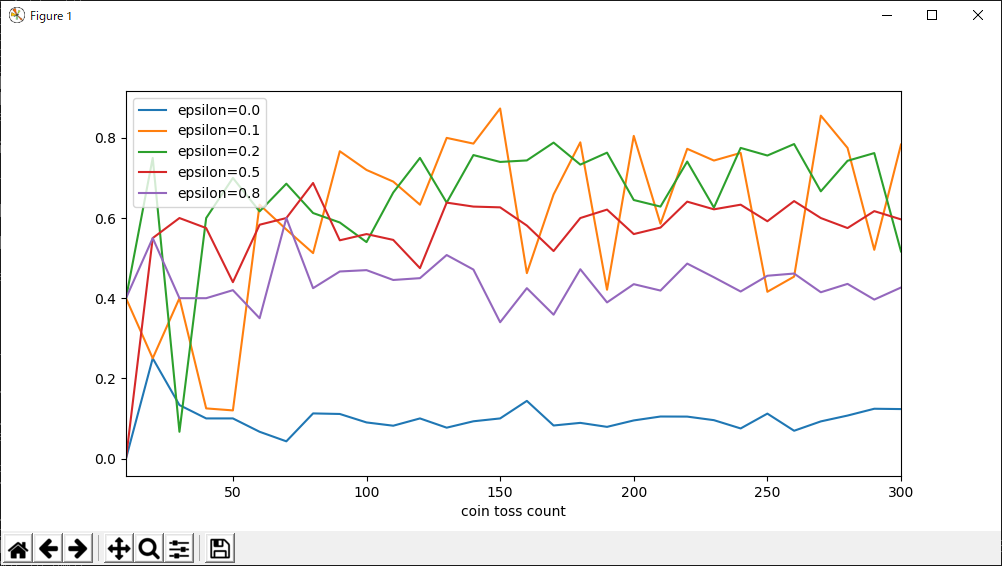
epsilon=0.1と0.2ではコイントスの回数とともに報酬が向上していることが分かります。
参考
Pythonで学ぶ強化学習 -入門から実践まで- サンプルコード