PyTorchはディープラーニング用パッケージです。
PyTorchを使用して手書き数字の画像データ(MNIST)を分類するディープラーニングを実装します。
まずは手書き数字の画像データMNISTをダウンロードします。
変数mnistにデータが格納されます。
1
2
3
|
from sklearn.datasets import fetch_openml
mnist = fetch_openml('mnist_784', version=1, data_home=".")
|
PyTorchによるディープラーニングは下記の手順で行います。
- データの前処理
- DataLoaderの作成
- ネットワークの構築
- 誤差関数と最適化手法の設定
- 学習と推論の設定
- 学習と推論の実行
データの前処理では、データをニューラルネットワークに投入できるように加工します。
1
2
3
4
5
6
7
|
X = mnist.data / 255
y = mnist.target
import numpy as np
y = np.array(y)
y = y.astype(np.int32)
|
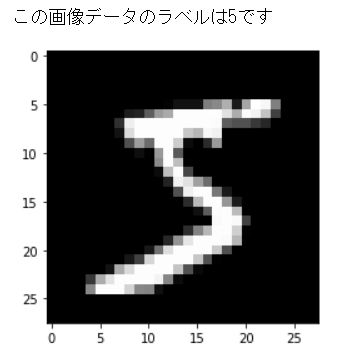
MNISTのデータの1つ目を可視化してみます。
1
2
3
4
5
6
|
import matplotlib.pyplot as plt
%matplotlib inline
plt.imshow(X[0].reshape(28, 28), cmap='gray')
print("この画像データのラベルは{:.0f}です".format(y[0]))
|
正規化したMNISTデータをPyTorchで扱えるようにDataLoaderという変数に変換します。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
import torch
from torch.utils.data import TensorDataset, DataLoader
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=1/7, random_state=0)
X_train = torch.Tensor(X_train)
X_test = torch.Tensor(X_test)
y_train = torch.LongTensor(y_train)
y_test = torch.LongTensor(y_test)
ds_train = TensorDataset(X_train, y_train)
ds_test = TensorDataset(X_test, y_test)
loader_train = DataLoader(ds_train, batch_size=64, shuffle=True)
loader_test = DataLoader(ds_test, batch_size=64, shuffle=False)
|
ニューラルネットワークを構築します。
‘fc’は全結合(Fully Connecteed)層を意味し、’relu’は活性化関数にReLU関数を使用することを意味します。
1
2
3
4
5
6
7
8
9
10
11
|
from torch import nn
model = nn.Sequential()
model.add_module('fc1', nn.Linear(28*28*1, 100))
model.add_module('relu1', nn.ReLU())
model.add_module('fc2', nn.Linear(100, 100))
model.add_module('relu2', nn.ReLU())
model.add_module('fc3', nn.Linear(100, 10))
print(model)
|

ネットワークの誤差関数と最適化手法の設定を行います。
分類問題では誤差関数にクロスエントロピー誤差関数を使用します。
最適化手法にはAdamというアルゴリズムを使います。
1
2
3
4
5
6
7
8
|
from torch import optim
loss_fn = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.01)
|
学習と推論での動作を設定します。
学習では訓練データを入力して出力を求め、出力と正解との誤差を計算し、誤差をバックプロパゲーションして結合パラメータを更新・学習させます。
引数のepochとはデータを一通り使用する1試行のことを意味します。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
def train(epoch):
model.train()
for data, targets in loader_train:
optimizer.zero_grad()
outputs = model(data)
loss = loss_fn(outputs, targets)
loss.backward()
optimizer.step()
print("epoch{}:終了\n".format(epoch))
|
推論ではテストデータを入力して出力を求め、正解と一致した割合を計算します。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
def test():
model.eval()
correct = 0
with torch.no_grad():
for data, targets in loader_test:
outputs = model(data)
_, predicted = torch.max(outputs.data, 1)
correct += predicted.eq(targets.data.view_as(predicted)).sum()
data_num = len(loader_test.dataset)
print('\nテストデータの正解率: {}/{} ({:.0f}%)\n'.format(correct, data_num, 100. * correct / data_num))
|
試しに学習をせずにテストデータで推論してみます。
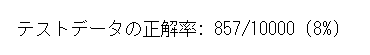
正解率は8%となりました。
次にニューラルネットワークの結合パラメータを学習させてから推論を行います。
6万件の訓練データに対して3epoch学習させます。
1
2
3
4
5
|
for epoch in range(3):
train(epoch)
test()
|

学習後には正解率が95%となり、手書き数字をほぼ正しく認識できるようになりました
試しに2020番目の画像データ推論し、予測結果と画像データ、正解を表示してみます。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
index = 2020
model.eval()
data = X_test[index]
output = model(data)
_, predicted = torch.max(output.data, 0)
print("予測結果は{}".format(predicted))
X_test_show = (X_test[index]).numpy()
plt.imshow(X_test_show.reshape(28, 28), cmap='gray')
print("この画像データの正解ラベルは{:.0f}です".format(y_test[index]))
|
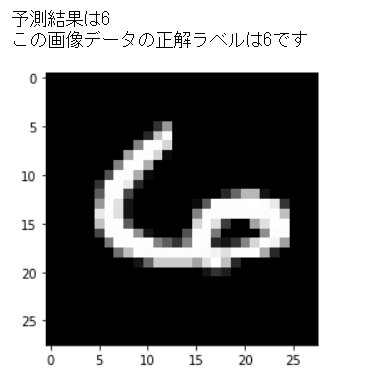
なかなか癖のある数字ですが、正しく判定できていることが分かります。
(Google Colaboratoryで動作確認しています。)
参考
>
つくりながら学ぶ!深層強化学習 サポートページ